红黑树——R-B Tree,全称是Red-Black Tree
红黑树的特性:
- 每个节点或者是黑色,或者是红色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
正是由于这些原因使得红黑树是一个平衡二叉树
第一步: 将红黑树当作一颗二叉查找树,将节点插入。
- 红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然是一颗二叉查找树。也就意味着,树的键值仍然是有序的。此外,无论是左旋还是右旋,若旋转之前这棵树是二叉查找树,旋转之后它一定还是二叉查找树。这也就意味着,任何的旋转和重新着色操作,都不会改变它仍然是一颗二叉查找树的事实。
第二步:将插入的节点着色为”红色”。
- 将插入的节点着色为红色,不会违背”特性(5)”!
第三步: 通过一系列的旋转或着色等操作,使之重新成为一颗红黑树。
- 第二步中,将插入节点着色为”红色”之后,不会违背”特性(5)”。那它到底会违背哪些特性呢?
- 对于”特性(1)”,显然不会违背了。因为我们已经将它涂成红色了。
- 对于”特性(2)”,显然也不会违背。在第一步中,我们是将红黑树当作二叉查找树,然后执行的插入操作。而根据二叉查找数的特点,插入操作不会改变根节点。所以,根节点仍然是黑色。
- 对于”特性(3)”,显然不会违背了。这里的叶子节点是指的空叶子节点,插入非空节点并不会对它们造成影响。
- 对于”特性(4)”,是有可能违背的!
- 那接下来,想办法使之”满足特性(4)”,就可以将树重新构造成红黑树了。
HashTable
- 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
- 初始size为11,扩容:newsize = olesize*2+1
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
HashMap
- 底层数组+链表实现,可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
- 计算index方法:index = hash & (tab.length – 1)
HashCode
- 考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?
- 当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值,实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了,说通俗一点:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。
- 也就是说对于两个对象,如果调用equals方法得到的结果为true,则两个对象的hashcode值必定相等;
- 如果equals方法得到的结果为false,则两个对象的hashcode值不一定不同;
- 如果两个对象的hashcode值不等,则equals方法得到的结果必定为false;
- 如果两个对象的hashcode值相等,则equals方法得到的结果未知。
- 在重写equals方法的同时,必须重写hashCode方法
- 所以在hashmap进行get操作时,因为得到的hashcdoe值不同(注意,上述代码也许在某些情况下会得到相同的hashcode值,不过这种概率比较小,因为虽然两个对象的存储地址不同也有可能得到相同的hashcode值),所以导致在get方法中for循环不会执行,直接返回null
- 所以如果你的hashCode方法依赖于对象中易变的数据,用户就要当心了,因为此数据发生变化时,hashCode()方法就会生成一个不同的散列码
HashMap的初始值还要考虑加载因子:
- 哈希冲突:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较。
- 加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
- 空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。
HashMap和Hashtable都是用hash算法来决定其元素的存储,因此HashMap和Hashtable的hash表包含如下属性:
- 容量(capacity):hash表中桶的数量
- 初始化容量(initial capacity):创建hash表时桶的数量,HashMap允许在构造器中指定初始化容量
- 尺寸(size):当前hash表中记录的数量
- 负载因子(load factor):负载因子等于“size/capacity”。负载因子为0,表示空的hash表,0.5表示半满的散列表,依此类推。轻负载的散列表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)
除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
HashMap和Hashtable的构造器允许指定一个负载极限,HashMap和Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。
“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:
- 较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询)
- 较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销
- 程序猿可以根据实际情况来调整“负载极限”值。
ConcurrentHashMap
- 底层采用分段的数组+链表实现,线程安全
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
- Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
- 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
在HashMap中,null可以作为键,这样的键只有一个,但可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该key,也可以表示该key所对应的value为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个key,应该用containsKey()方法来判断。而在Hashtable中,无论是key还是value都不能为null。
Hashtable是线程安全的,它的方法是同步的,可以直接用在多线程环境中。而HashMap则不是线程安全的,在多线程环境中,需要手动实现同步机制。
Hashtable与HashMap另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。
ConcurrentHashMap是使用了锁分段技术来保证线程安全的。
锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap提供了与Hashtable和SynchronizedMap不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
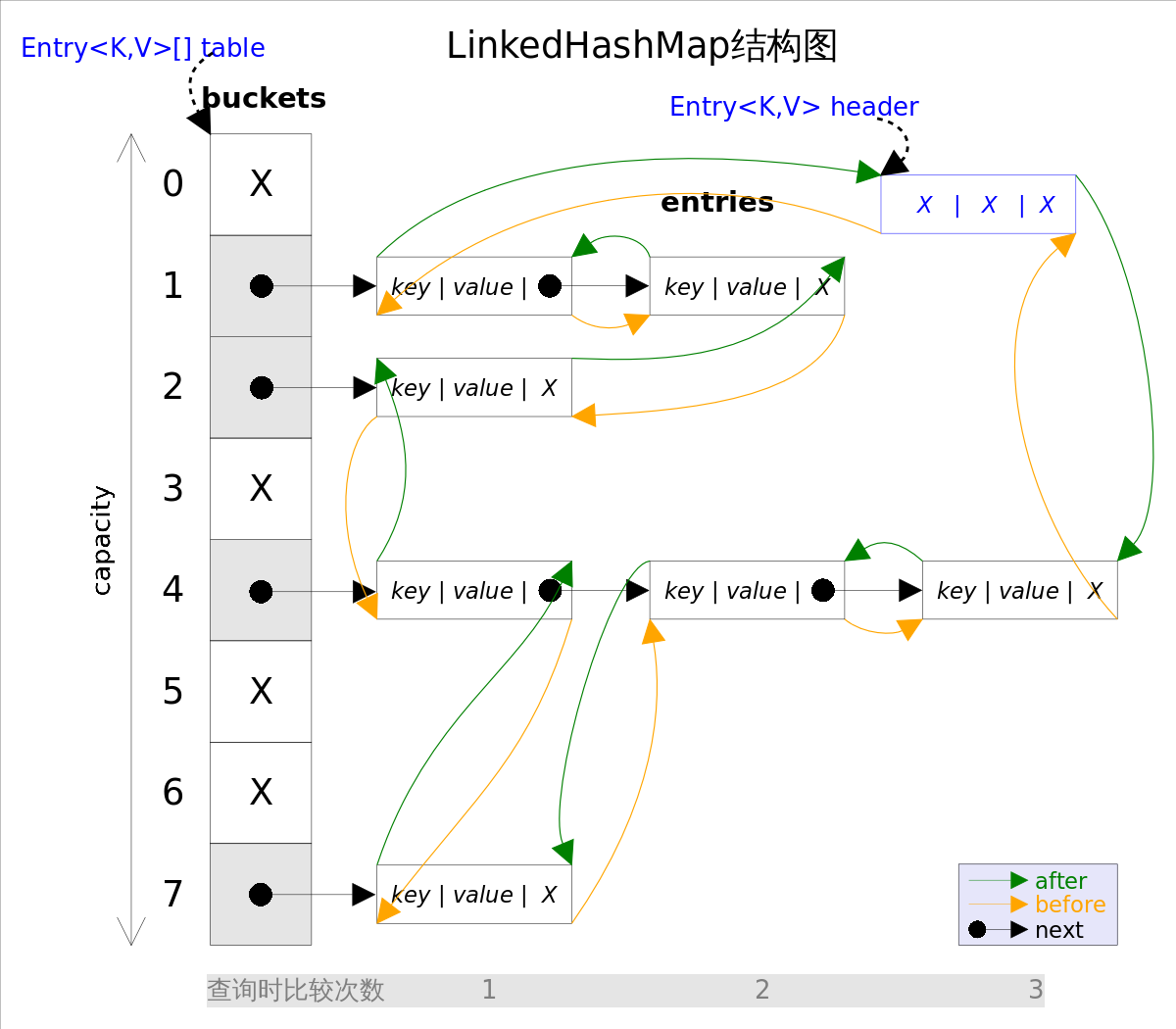
LinkedHashMap
大多数情况下,只要不涉及线程安全问题,Map基本都可以使用HashMap,不过HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序。HashMap的这一缺点往往会带来困扰,因为有些场景,我们期待一个有序的Map。
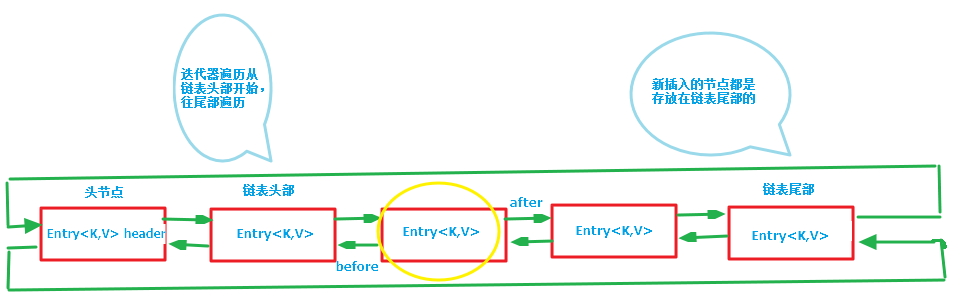
这个时候,LinkedHashMap就闪亮登场了,它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序。LinkedHashMap就是HashMap+双向链表。
| 问题 | 结论 |
|---|---|
| LinkedHashMap是否允许空 | Key和Value都允许空 |
| LinkedHashMap是否允许重复数据 | Key重复会覆盖、Value允许重复 |
| LinkedHashMap是否有序 | 有序 |
| LinkedHashMap是否线程安全 | 非线程安全 |
Hashmap 如果链表过长
哈希碰撞会对hashMap的性能带来灾难性的影响。如果多个hashCode()的值落到同一个桶内的时候,这些值是存储到一个链表中的。最坏的情况下,所有的key都映射到同一个桶中,这样hashmap就退化成了一个链表——查找时间从O(1)到O(n)。
Java 7随着HashMap的大小的增长,get()方法的开销也越来越大。由于所有的记录都在同一个桶里的超长链表内,平均查询一条记录就需要遍历一半的列表。因此从图上可以看到,它的时间复杂度是O(n)。
不过Java 8的表现要好许多!它是一个log的曲线,因此它的性能要好上好几个数量级。尽管有严重的哈希碰撞,已是最坏的情况了,但这个同样的基准测试在JDK8中的时间复杂度是O(logn)。
为什么会有这么大的性能提升?
- 这个优化在JEP-180中已经提到了。如果某个桶中的记录过大的话(当前是
TREEIFY_THRESHOLD= 8),HashMap会动态的使用一个专门的treemap(红黑树)实现来替换掉它。这样做的结果会更好,是O(logn),而不是糟糕的O(n)。它是如何工作的?前面产生冲突的那些KEY对应的记录只是简单的追加到一个链表后面,这些记录只能通过遍历来进行查找。 - 但是超过这个阈值后
HashMap开始将列表升级成一个二叉树,使用哈希值作为树的分支变量,如果两个哈希值不等,但指向同一个桶的话,较大的那个会插入到右子树里。如果哈希值相等,HashMap希望key值最好是实现了Comparable接口的,这样它可以按照顺序来进行插入。这对HashMap的key来说并不是必须的,不过如果实现了当然最好。如果没有实现这个接口,在出现严重的哈希碰撞的时候,你就并别指望能获得性能提升了。
HashMap在JDK1.8及以后的版本中引入了红黑树结构,若桶中链表元素个数大于等于8时,链表转换成树结构;若桶中链表元素个数小于等于6时,树结构还原成链表。因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
还有选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
这个性能提升有什么用处?
- 比方说恶意的程序,如果它知道我们用的是哈希算法,它可能会发送大量的请求,导致产生严重的哈希碰撞。然后不停的访问这些key就能显著的影响服务器的性能,这样就形成了一次
拒绝服务攻击(DoS)。JDK 8中从O(n)到O(logn)的飞跃,可以有效地防止类似的攻击,同时也让HashMap性能的可预测性稍微增强了一些。我希望这个提升能最终说服你的老大同意升级到JDK 8来。
SparseArray——稀疏数组

使用下面的语句创建一个key为整数的hashmap时,AS会提出一个提示:建议使用SparseArray替代HashMap来获得更好的表现
HashMap<Integer,Object> map = new HashMap<Integer,Object>;
分析SparseArray源码:
public class SparseArray<E> implements Cloneable {
private static final Object DELETED = new Object();
private boolean mGarbage = false;
private int[] mKeys;
private Object[] mValues;
private int mSize;
/**
* Creates a new SparseArray containing no mappings.
*/
public SparseArray() {
this(10);
}
/**
* Creates a new SparseArray containing no mappings that will not
* require any additional memory allocation to store the specified
* number of mappings. If you supply an initial capacity of 0, the
* sparse array will be initialized with a light-weight representation
* not requiring any additional array allocations.
*/
public SparseArray(int initialCapacity) {
if (initialCapacity == 0) {
mKeys = EmptyArray.INT;
mValues = EmptyArray.OBJECT;
} else {
mValues = ArrayUtils.newUnpaddedObjectArray(initialCapacity);
mKeys = new int[mValues.length];
}
mSize = 0;
}
···
···
/**
* Gets the Object mapped from the specified key, or the specified Object
* if no such mapping has been made.
*/
@SuppressWarnings("unchecked")
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
return (E) mValues[i];
}
}
/**
* Removes the mapping from the specified key, if there was any.
*/
public void delete(int key) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
if (mValues[i] != DELETED) {
mValues[i] = DELETED;
mGarbage = true;
}
}
}
······
private void gc() {
// Log.e("SparseArray", "gc start with " + mSize);
int n = mSize;
int o = 0;
int[] keys = mKeys;
Object[] values = mValues;
for (int i = 0; i < n; i++) {
Object val = values[i];
if (val != DELETED) {
if (i != o) {
keys[o] = keys[i];
values[o] = val;
values[i] = null;
}
o++;
}
}
mGarbage = false;
mSize = o;
// Log.e("SparseArray", "gc end with " + mSize);
}
/**
* Adds a mapping from the specified key to the specified value,
* replacing the previous mapping from the specified key if there
* was one.
*/
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
mValues[i] = value;
} else {
i = ~i;
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}
···
···
···
···
/**
* Returns the index for which {@link #keyAt} would return the
* specified key, or a negative number if the specified
* key is not mapped.
*/
public int indexOfKey(int key) {
if (mGarbage) {
gc();
}
return ContainerHelpers.binarySearch(mKeys, mSize, key);
}
/**
* Returns an index for which {@link #valueAt} would return the
* specified key, or a negative number if no keys map to the
* specified value.
* <p>Beware that this is a linear search, unlike lookups by key,
* and that multiple keys can map to the same value and this will
* find only one of them.
* <p>Note also that unlike most collections' {@code indexOf} methods,
* this method compares values using {@code ==} rather than {@code equals}.
*/
public int indexOfValue(E value) {
if (mGarbage) {
gc();
}
for (int i = 0; i < mSize; i++) {
if (mValues[i] == value) {
return i;
}
}
return -1;
}
···
···
/**
* Puts a key/value pair into the array, optimizing for the case where
* the key is greater than all existing keys in the array.
*/
public void append(int key, E value) {
if (mSize != 0 && key <= mKeys[mSize - 1]) {
put(key, value);
return;
}
if (mGarbage && mSize >= mKeys.length) {
gc();
}
mKeys = GrowingArrayUtils.append(mKeys, mSize, key);
mValues = GrowingArrayUtils.append(mValues, mSize, value);
mSize++;
}
···
···
}
阅读完源码可以得到以下几点关键信息:
- SparseArray默认初始size为10
- 通过一个
int数组和一个Object数组来存储Key-Value对 - get方法通过key获取value使用的查找方式是
二分查找,因此SparseArray在大量数据,千以上时,会效率较低 - 相比与HashMap,其采用
时间换空间的方式,使用更少的内存来提高手机APP的运行效率
android.support.v4.util.ArrayMap
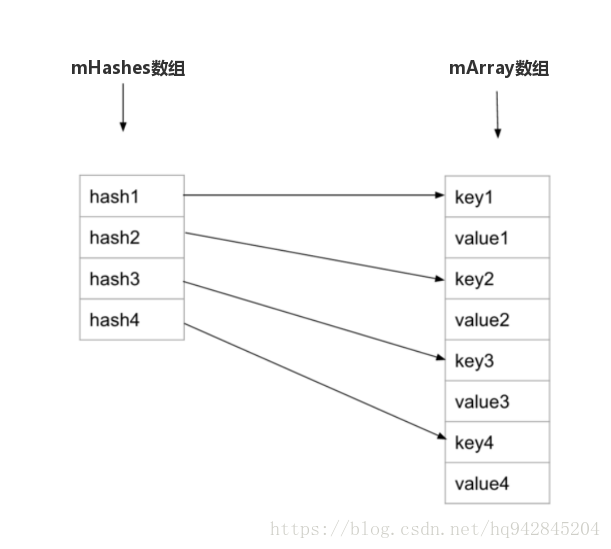
首先从ArrayMap的四个数组说起。
mHashes,用于保存key对应的hashCode;mArray,用于保存键值对(key,value),其结构为[key1,value1,key2,value2,key3,value3,……];- mBaseCache,缓存,如果ArrayMap的数据量从4,增加到8,用该数组保存之前使用的mHashes和mArray,这样如果数据量再变回4的时候,可以再次使用之前的数组,不需要再次申请空间,这样节省了一定的时间;
- mTwiceBaseCache,与mBaseCache对应,不过触发的条件是数据量从8增长到12。
上面提到的数据量有8增长到12,为什么不是16?这也算是ArrayMap的一个优化的点,它不是每次增长1倍,而是使用了如下方法(mSize+(mSize>>1)),即每次增加1/2。
结构:
普通内部类持有外部类引用的原理
内部类虽然和外部类写在同一个文件中,但是编译完成后,还是生成各自的class文件,内部类通过this访问外部类的成员。
- 编译器自动为内部类添加一个成员变量(实例化),这个成员变量的类型和外部类的类型相同, 这个成员变量就是指向外部类对象(this)的引用;
- 编译器自动为内部类的构造方法添加一个参数, 参数的类型是外部类的类型, 在构造方法内部使用这个参数为内部类中添加的成员变量赋值;
- 在调用内部类的构造函数初始化内部类对象时,会默认传入外部类的引用。
而对于静态内部类:
- 创建静态内部类的时候是不需要讲静态内部类的实例对象绑定到外部类的实例对象上。
- 静态内部类属于外部类,而不是属于外部类的对象。
- 只能访问外部类的静态成员变量或者静态方法。
- 生成静态内部类对象的方式:Outer.Inner inner = new Outer.Inner()。
使用static来修饰一个内部类,则这个内部类就属于外部类本身,而不属于外部类的某个对象。称为静态内部类(也可称为类内部类),这样的内部类是类级别的,static关键字的作用是把类的成员变成类相关,而不是实例相关
static变量是静态变量,当加载类时即已加载,非static变量实例对象时加载。
static变量是静态变量当改变其中的值,其它实例中的该static变量也会改变,非static变量只会在具体所在的那个对象中改变,不会影响其它实例。
注意:
- 非静态内部类中不允许定义静态成员,但是是可以定义静态的成员变量的,只是必须加上final修饰符
- 外部类的静态成员不可以直接使用非静态内部类
- 静态内部类,不能访问外部类的实例成员,只能访问外部类的类成员
malloc 与 new
属性- new/delete是C++运算符,需要编译器支持。malloc/free是库函数,需要头文件支持。
参数- 使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算。而malloc则需要显式地指出所需内存的尺寸。
返回类型- new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void * ,需要通过强制类型转换将void*指针转换成我们需要的类型。
分配失败- new内存分配失败时,会抛出bac_alloc异常。malloc分配内存失败时返回NULL。
自定义类型- new会先调用operator new函数,申请足够的内存(通常底层使用malloc实现)。然后调用类型的构造函数,初始化成员变量,最后返回自定义类型指针。delete先调用析构函数,然后调用operator delete函数释放内存(通常底层使用free实现)。
- malloc/free是库函数,只能动态的申请和释放内存,无法强制要求其做自定义类型对象构造和析构工作。
重载- C++允许重载new/delete操作符,特别的,布局new的就不需要为对象分配内存,而是指定了一个地址作为内存起始区域,new在这段内存上为对象调用构造函数完成初始化工作,并返回此地址。而malloc不允许重载。
内存区域- new操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。而堆是操作系统中的术语,是操作系统所维护的一块特殊内存,用于程序的内存动态分配,C语言使用malloc从堆上分配内存,使用free释放已分配的对应内存。自由存储区不等于堆,如上所述,布局new就可以不位于堆中。
Java 多态
多态是同一个行为具有多个不同表现形式或形态的能力。
多态的优点
- 消除类型之间的耦合关系
- 可替换性
- 可扩充性
- 接口性
- 灵活性
- 简化性
多态存在的三个必要条件
- 继承
- 重写
- 父类引用指向子类对象
Parent p = new Child();
多态的实现方式
- 方式一:重写:
- 这个内容已经在上一章节详细讲过,就不再阐述,详细可访问:Java 重写(Override)与重载(Overload)。
- 方式二:接口
- 生活中的接口最具代表性的就是插座,例如一个三接头的插头都能接在三孔插座中,因为这个是每个国家都有各自规定的接口规则,有可能到国外就不行,那是因为国外自己定义的接口类型。
- java中的接口类似于生活中的接口,就是一些方法特征的集合,但没有方法的实现。具体可以看 java接口 这一章节的内容。
- 方式三:抽象类和抽象方法
Java 抽象类
在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。
抽象类除了不能实例化对象之外,类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样。
由于抽象类不能实例化对象,所以抽象类必须被继承,才能被使用。也是因为这个原因,通常在设计阶段决定要不要设计抽象类。
父类包含了子类集合的常见的方法,但是由于父类本身是抽象的,所以不能使用这些方法。
在Java中抽象类表示的是一种继承关系,一个类只能继承一个抽象类,而一个类却可以实现多个接口。
抽象方法
如果你想设计这样一个类,该类包含一个特别的成员方法,该方法的具体实现由它的子类确定,那么你可以在父类中声明该方法为抽象方法。
Abstract 关键字同样可以用来声明抽象方法,抽象方法只包含一个方法名,而没有方法体。
抽象方法没有定义,方法名后面直接跟一个分号,而不是花括号。
public abstract class Employee
{
private String name;
private String address;
private int number;
public abstract double computePay();
//其余代码
}
声明抽象方法会造成以下两个结果:
如果一个类包含抽象方法,那么该类必须是抽象类。任何子类必须重写父类的抽象方法,或者声明自身为抽象类。
抽象类总结规定
- 抽象类
不能被实例化(初学者很容易犯的错),如果被实例化,就会报错,编译无法通过。只有抽象类的非抽象子类可以创建对象。 - 抽象类中
不一定包含抽象方法,但是有抽象方法的类必定是抽象类。 - 抽象类中的
抽象方法只是声明,不包含方法体,就是不给出方法的具体实现也就是方法的具体功能。 - 构造方法,类方法(用 static 修饰的方法)不能声明为抽象方法。
- 抽象类的子类必须给出抽象类中的抽象方法的具体实现,除非该子类也是抽象类。
Java interface
在JAVA编程语言中是一个抽象类型,是抽象方法的集合,接口通常以interface来声明。一个类通过继承接口的方式,从而来继承接口的抽象方法。
接口并不是类,编写接口的方式和类很相似,但是它们属于不同的概念。类描述对象的属性和方法。接口则包含类要实现的方法。
除非实现接口的类是抽象类,否则该类要定义接口中的所有方法。
接口无法被实例化,但是可以被实现。一个实现接口的类,必须实现接口内所描述的所有方法,否则就必须声明为抽象类。另外,在 Java 中,接口类型可用来声明一个变量,他们可以成为一个空指针,或是被绑定在一个以此接口实现的对象。
注意匿名类实现interface的情况!
fab.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Bundle bundle = new Bundle();
Intent intent = new Intent(MainActivity.this, NoteNewActivity.class);
intent.putExtra("groupName",groupName);
intent.putExtra("NewOrEdit","New");
startActivity(intent);
}
});
新建匿名类,这样做其实没有new 一个 接口,而是new 了一个没有名字的 类A,A implements 了 Listener,然后实现了 onClick(),他仅仅是简写了而已,其实并没有new 接口
接口与类的区别:
- 接口不能用于实例化对象。
- 接口没有构造方法。
- 接口中所有的方法必须是抽象方法。
- 接口不能包含成员变量,除了 static 和 final 变量。
- 接口不是被类继承了,而是要被类实现。
- 接口支持多继承。
接口特性
- 接口中每一个方法也是
隐式抽象的,接口中的方法会被隐式的指定为 public abstract(只能是 public abstract,其他修饰符都会报错)。 - 接口中可以含有变量,但是接口中的变量会被
隐式的指定为 public static final 变量(并且只能是 public,用 private 修饰会报编译错误)。 - 接口中的方法是不能在接口中实现的,只能由实现接口的类来实现接口中的方法。
抽象类和接口的区别
- 抽象类中的方法可以有方法体,就是能实现方法的具体功能,但是接口中的方法不行。
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的。
- 接口中不能含有静态代码块以及静态方法(用 static 修饰的方法),而抽象类是可以有静态代码块和静态方法。
- 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
接口有以下特性:
- 接口是隐式抽象的,当声明一个接口的时候,不必使用abstract关键字。
- 接口中每一个方法也是隐式抽象的,声明时同样不需要abstract关键字。
- 接口中的方法都是公有的。
interface Animal {
public void eat();
public void travel();
}
public class MammalInt implements Animal{
public void eat(){
System.out.println("Mammal eats");
}
public void travel(){
System.out.println("Mammal travels");
}
public int noOfLegs(){
return 0;
}
public static void main(String args[]){
MammalInt m = new MammalInt();
m.eat();
m.travel();
}
}
Java 虚继承与接口interface
| Abstract class | Interface | |
|---|---|---|
| 实例化 | 不能 | 不能 |
| 类 | 一种继承关系,一个类只能使用一次继承关系。可以通过继承多个接口实现多重继承 | 一个类可以实现多个interface |
| 数据成员 | 可有自己的 | 静态的不能被修改即必须是static final,一般不在此定义 |
| 方法 | 可以私有的,非abstract方法,必须实现 | 不可有私有的,默认是public,abstract 类型 |
| 变量 | 可有私有的,默认是friendly 型,其值可以在子类中重新定义,也可以重新赋值 | 不可有私有的,默认是public static final 型,且必须给其初值,实现类中不能重新定义,不能改变其值。 |
| 设计理念 | 表示的是“is-a”关系 | 表示的是“like-a”关系 |
| 实现 | 需要继承,要用extends | 要用implements |
声明方法的存在而不去实现它的类被叫做抽象类(abstract class),它用于要创建一个体现某些基本行为的类,并为该类声明方法,但不能在该类中实现该类的情况。不能创建abstract 类的实例。然而可以创建一个变量,其类型是一个抽象类,并让它指向具体子类的一个实例。不能有抽象构造函数或抽象静态方法。Abstract 类的子类为它们父类中的所有抽象方法提供实现,否则它们也是抽象类为。取而代之,在子类中实现该方法。知道其行为的其它类可以在类中实现这些方法。
接口(interface)是抽象类的变体。在接口中,所有方法都是抽象的。多继承性可通过实现 这样的接口而获得。接口中的所有方法都是抽象的,没有一个有程序体。接口只可以定义static final成员变量。接口的实现与子类相似,除了该实现类不能从接口定义中继承行为。当类实现特殊接口时,它定义(即将程序体给予)所有这种接口的方法。 然后,它可以在实现了该接口的类的任何对象上调用接口的方法。由于有抽象类,它允许使用接口名作为引用变量的类型。通常的动态联编将生效。引用可以转换到 接口类型或从接口类型转换,instanceof 运算符可以用来决定某对象的类是否实现了接口。
接口可以继承接口。抽象类可以实现(implements)接口,抽象类是可以继承实体类,但前提是实体类必须有明确的构造函数。接口更关注“能实现什么功能”,而不管“怎么实现的”。
- 相同点
- 两者都是抽象类,都不能实例化。
- interface实现类及abstrct class的子类都必须要实现已经声明的抽象方法。
- 不同点
- interface需要实现,要用implements,而abstract class需要继承,要用extends。
- 一个类可以实现多个interface,但一个类只能继承一个abstract class。
- interface强调特定功能的实现,而abstract class强调所属关系。
- 尽管interface实现类及abstrct class的子类都必须要实现相应的抽象方法,但实现的形式不同。interface中的每一个方法都是抽象方法,都只是声明的 (declaration, 没有方法体),实现类必须要实现。而abstract class的子类可以有选择地实现。
- 这个选择有两点含义:
- 一是Abastract class中并非所有的方法都是抽象的,只有那些冠有abstract的方法才是抽象的,子类必须实现。那些没有abstract的方法,在Abstrct class中必须定义方法体。
- 二是abstract class的子类在继承它时,对非抽象方法既可以直接继承,也可以覆盖;而对抽象方法,可以选择实现,也可以通过再次声明其方法为抽象的方式,无需实现,留给其子类来实现,但此类必须也声明为抽象类。既是抽象类,当然也不能实例化。
- abstract class是interface与Class的中介。
- interface是完全抽象的,只能声明方法,而且只能声明pulic的方法,不能声明private及protected的方法,不能定义方法体,也 不能声明实例变量。然而,interface却可以声明常量变量,并且在JDK中不难找出这种例子。但将常量变量放在interface中违背了其作为接 口的作用而存在的宗旨,也混淆了interface与类的不同价值。如果的确需要,可以将其放在相应的abstract class或Class中。
- abstract class在interface及Class中起到了承上启下的作用。一方面,abstract class是抽象的,可以声明抽象方法,以规范子类必须实现的功能;另一方面,它又可以定义缺省的方法体,供子类直接使用或覆盖。另外,它还可以定义自己 的实例变量,以供子类通过继承来使用。
- interface的应用场合
- 类与类之前需要特定的接口进行协调,而不在乎其如何实现。
- 作为能够实现特定功能的标识存在,也可以是什么接口方法都没有的纯粹标识。
- 需要将一组类视为单一的类,而调用者只通过接口来与这组类发生联系。
- 需要实现特定的多项功能,而这些功能之间可能完全没有任何联系。
- abstract class的应用场合
一句话,在既需要统一的接口,又需要实例变量或缺省的方法的情况下,就可以使用它。最常见的有:
- 定义了一组接口,但又不想强迫每个实现类都必须实现所有的接口。可以用abstract class定义一组方法体,甚至可以是空方法体,然后由子类选择自己所感兴趣的方法来覆盖。
- 某些场合下,只靠纯粹的接口不能满足类与类之间的协调,还必需类中表示状态的变量来区别不同的关系。abstract的中介作用可以很好地满足这一点。
- 规范了一组相互协调的方法,其中一些方法是共同的,与状态无关的,可以共享的,无需子类分别实现;而另一些方法却需要各个子类根据自己特定的状态来实现特定的功能。
final finally finalize 关键字
1.简单区别:
final用于声明属性,方法和类,分别表示属性不可交变,方法不可覆盖,类不可继承。finally是异常处理语句结构的一部分,表示总是执行。finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,供垃圾收集时的其他资源回收,例如关闭文件等。2.中等区别:
虽然这个单词在Java中都存在,但是并没太多关联:
final:java中的关键字,修饰符。- 如果一个类被声明为final,就意味着它不能再派生出新的子类,不能作为父类被继承。因此,一个类不能同时被声明为abstract抽象类的和final的类。
- 如果将变量或者方法声明为final,可以保证它们在使用中不被改变.
- 被声明为final的变量必须在声明时给定初值,而在以后的引用中只能读取,不可修改。
- 被声明final的方法只能使用,不能重写重载,但是并不影响它被子类继承。
finally:java的一种异常处理机制。
- finally是对Java异常处理模型的最佳补充。finally结构使代码
总会执行,而不管无异常发生。使用finally可以维护对象的内部状态,并可以清理非内存资源。特别是在关闭数据库连接这方面,如果程序员把数据库连接的close()方法放到finally中,就会大大降低程序出错的几率。finalize:Java中的一个方法名。 - Java技术使用finalize()方法在
垃圾收集器将对象从内存中清除出去前,做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没被引用时对这个对象调用的。它是在Object类中定义的,因此所的类都继承了它。子类覆盖finalize()方法以整理系统资源或者执行其他清理工作。finalize()方法是在垃圾收集器删除对象之前对这个对象调用的。
final
定义变量
如果一个变量或方法参数被final修饰,就表示它只能被赋值一次,但是JAVA虚拟机为变量设定的默认值不记作一次赋值。被final修饰的变量必须被初始化。初始化的方式以下几种:
- 在定义的时候初始化。
- final变量可以在初始化块中初始化,不可以在静态初始化块中初始化。
- 静态final变量可以在定义时初始化,也可以在静态初始化块中初始化,不可以在初始化块中初始化。
- final变量还可以在类的构造器中初始化,但是静态final变量不可以。
定义方法
当final用来定义一个方法时,它表示这个方法不可以被子类重写,但是并不影响它被子类继承。
public class ParentClass{
public final void TestFinal(){
System.out.println("父类--这是一个final方法");
}
}
public class SubClass extends ParentClass{
//子类无法重写(override父类的final方法,否则编译时会报错
/* public void TestFinal(){
System.out.println("子类--重写final方法");
} */
public static void main(String[]args){
SubClass sc = new SubClass();
sc.TestFinal();
}
}
具有private访问权限的方法也可以增加final修饰,但是由于子类无法继承private方法,因此也无法重写它。编译器在处理private方法时,是照final方来对待的,这样可以提高该方法被调用时的效率。不过子类仍然可以定义同父类中private方法具同样结构的方法,但是这并不会产生重写的效果(即与父类的同名方法是不同的两个方法),而且它们之间也不存在必然联系。
定义类
我们最常用的String类就是final的。由于final类不允许被继承,编译器在处理时把它的所有方法都当作final的,因此final类比普通类拥更高的效率。而由关键字abstract定义的抽象类含必须由继承自它的子类重载实现的抽象方法,因此无法同时用final和abstract来修饰同一个类。同样的道理,final也不能用来修饰接口。
final的类的所方法都不能被重写,但这并不表示final的类的属性全部都是不能改变的(变量值也是不可改变的,要想做到final类的属性值不可改变,必须给它增加final修饰,请看下面的例子:
public final class FinalTest{
int i =20;
final int j=50;
public static void main(String[] args){
FinalTest ft = new FinalTest();
ft.i = 99;/*final类FinalTest的属性值 i是可以改变的,因为属性值i前面没final修饰*/
//ft.j=49;//报错....因为j属性是final的不可以改变。
System.out.println(ft.i);
}
}
finally
接下来我们一起回顾一下finally的用法。finally只能用在try/catch语句中并且附带着一个语句块,表示这段语句最终总是被执行。请看下面的代码:
public final class FinallyTest {
//测试return语句
//结果显示:编译器在编译return new ReturnClass();时,
//将它分成了两个步骤,new ReturnClass()和return,前一个创建对象的语句是在finally语句块之前被执行的,
//而后一个return语句是在finally语句块之后执行的,也就是说finally语句块是在程序退出方法之前被执行的
public ReturnClass testReturn() {
try {
return new ReturnClass();
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println("执行了finally语句");
}
return null;
}
//测试continue语句
public void testContinue(){
for(int i=0; i<3; i++){
try {
System.out.println(i);
if(i == 1){
System.out.println("con");
}
} catch(Exception e) {
e.printStackTrace();
} finally {
System.out.println("执行了finally语句");
}
}
}
//测试break语句
public void testBreak() {
for (int i=0; i<3; i++) {
try {
System.out.println(i);
if (i == 1) {
break;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println("执行了finally语句");
}
}
}
public static void main(String[] args) {
FinallyTest ft = new FinallyTest();
// 测试return语句
ft.testReturn();
System.out.println();
// 测试continue语句
ft.testContinue();
System.out.println();
// 测试break语句
ft.testBreak();
}
}
class ReturnClass {
public ReturnClass() {
System.out.println("执行了return语句");
}
}
运行结果如下:
执行了return语句
执行了finally语句
0
执行了finally语句
1
con
执行了finally语句
2
执行了finally语句
0
执行了finally语句
1
执行了finally语句
可见,return、continue和break都没能阻止finally语句块的执行。从输出的结果来看,return语句似乎在finally语句块之前执行了,事实真的如此吗?我们来想想看,return语句的作用是什么呢?是退出当前的方法,并将值或对象返回。如果 finally语句块是在return语句之后执行的,那么return语句被执行后就已经退出当前方法了,finally语句块又如何能被执行呢?因此,正确的执行顺序应该是这样的:编译器在编译return new ReturnClass();时,将它分成了两个步骤,new ReturnClass()和return,前一个创建对象的语句是在finally语句块之前被执行的,而后一个return语句是在finally语句块之后执行的,也就是说finally语句块是在程序退出方法之前被执行的。同样,finally语句块是在循环被跳过(continue和中断(break之前被执行的
finalize
关于Object类:
Object 是 Java 类库中的一个特殊类,也是所有类的父类。当一个类被定义后,如果没有指定继承的父类,那么默认父类就是 Object 类。
方法| 说明
-
Object clone() 创建与该对象的类相同的新对象 boolean equals(Object) 比较两对象是否相等 void finalize() 当垃圾回收器确定不存在对该对象的更多引用时,对象的圾回收器调用该方法 Class getClass() 返回一个对象运行时的实例类 int hashCode() 返回该对象的散列码值 void notify() 激活等待在该对象的监视器上的一个线程 void notifyAll() 激活等待在该对象的监视器上的全部线程 String toString() 返回该对象的字符串表示 void wait() 在其他线程调用此对象的 notify() 方法或 notifyAll() 方法前,导致当前线程等待
Object源码:
public class Object {
···
···
···
/**
* Called by the garbage collector on an object when garbage collection
* determines that there are no more references to the object.
* A subclass overrides the {@code finalize} method to dispose of
* system resources or to perform other cleanup.
* <p>
* The general contract of {@code finalize} is that it is invoked
* if and when the Java™ virtual
* machine has determined that there is no longer any
* means by which this object can be accessed by any thread that has
* not yet died, except as a result of an action taken by the
* finalization of some other object or class which is ready to be
* finalized. The {@code finalize} method may take any action, including
* making this object available again to other threads; the usual purpose
* of {@code finalize}, however, is to perform cleanup actions before
* the object is irrevocably discarded. For example, the finalize method
* for an object that represents an input/output connection might perform
* explicit I/O transactions to break the connection before the object is
* permanently discarded.
* <p>
* The {@code finalize} method of class {@code Object} performs no
* special action; it simply returns normally. Subclasses of
* {@code Object} may override this definition.
* <p>
* The Java programming language does not guarantee which thread will
* invoke the {@code finalize} method for any given object. It is
* guaranteed, however, that the thread that invokes finalize will not
* be holding any user-visible synchronization locks when finalize is
* invoked. If an uncaught exception is thrown by the finalize method,
* the exception is ignored and finalization of that object terminates.
* <p>
* After the {@code finalize} method has been invoked for an object, no
* further action is taken until the Java virtual machine has again
* determined that there is no longer any means by which this object can
* be accessed by any thread that has not yet died, including possible
* actions by other objects or classes which are ready to be finalized,
* at which point the object may be discarded.
* <p>
* The {@code finalize} method is never invoked more than once by a Java
* virtual machine for any given object.
* <p>
* Any exception thrown by the {@code finalize} method causes
* the finalization of this object to be halted, but is otherwise
* ignored.
*
* @throws Throwable the {@code Exception} raised by this method
* @see java.lang.ref.WeakReference
* @see java.lang.ref.PhantomReference
* @jls 12.6 Finalization of Class Instances
*/
protected void finalize() throws Throwable { }
}
由于finalize()属于Object类,因此所有类都有这个方法,Object的任意子类都可以重写(override该方法,在其中释放系统资源或者做其它的清理工作,如关闭输入输出流。
finalize()方法是在GC清理它所从属的对象时被调用的,如果执行它的过程中抛出了无法捕获的异常(uncaughtexception,GC将终止对改对象的清理,并且该异常会被忽略;直到下一次GC开始清理这个对象时,它的finalize()会被再次调用。
Thread.sleep() 和 Object.wait()
- 这两个方法来自不同的类分别是,sleep来自Thread类,和wait来自Object类。
sleep是Thread的静态类方法,谁调用的谁去睡觉,即使在a线程里调用了b的sleep方法,实际上还是a去睡觉,要让b线程睡觉要在b的代码中调用sleep。
- 最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
sleep不出让系统资源;wait是进入线程等待池等待,出让系统资源,其他线程可以占用CPU。一般wait不会加时间限制,因为如果wait线程的运行资源不够,再出来也没用,要等待其他线程调用notify/notifyAll唤醒等待池中的所有线程,才会进入就绪队列等待OS分配系统资源。sleep(milliseconds)可以用时间指定使它自动唤醒过来,如果时间不到只能调用interrupt()强行打断。
Thread.Sleep(0)的作用是“触发操作系统立刻重新进行一次CPU竞争”。
- 使用范围:wait,notify和notifyAll只能在
同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用synchronized(x){ x.notify() //或者wait() } - sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
关于wait()方法
- 使用wait()、notify()和notifyAll()时需要先对调用对象加锁,调用wait()方法后会释放锁。
- 调用wait()方法之后,线程状态由RUNNING变为WAITING,并将当前线程放置到对象的等待队列中。
- notify()或notifyAll()方法调用后,等待线程不会立刻从wait()中返回,需要等该线程释放锁之后,才有机会获取锁,之后从wait()返回。
- notify()方法将等待队列中的一个等待线程从等待队列中移动到同步队列中;
- notifyAll()方法则是把等待队列中的所有线程都移动到同步队列中,被移动的线程状态从WAITING变为BLOCKED。
- 从wait()方法返回的前提是,该线程获得了调用对象的锁。
volatile
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
- 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是
立即可见的。 禁止进行指令重排序。
先看一段代码,假如线程1先执行,线程2后执行:
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;
这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
- 第一:使用volatile关键字会强制将修改的值立即写入主存;
- 第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
- 第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效,然后线程1读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。
那么线程1读取到的就是最新的正确的值。
原子性?
volatile无法保证对变量的任何操作都是原子性的,只能保证变量的可见性。
有序性?
volatile关键字能禁止指令重排序,所以volatile能在一定程度上保证有序性。
volatile关键字禁止指令重排序有两层意思:
- 当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
- 在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
原理
前面讲述了源于volatile关键字的一些使用,下面我们来探讨一下volatile到底如何保证可见性和禁止指令重排序的。
下面这段话摘自《深入理解Java虚拟机》:
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也称内存栅栏),内存屏障会提供3个功能:
- 它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
- 它会强制将对缓存的修改操作立即写入主存;
- 如果是写操作,它会导致其他CPU中对应的缓存行无效。
使用volatile关键字的场景
synchronized关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。通常来说,使用volatile必须具备以下2个条件:
- 对变量的写操作不依赖于当前值
- 该变量没有包含在具有其他变量的不变式中
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
事实上,我的理解就是上面的2个条件需要保证操作是原子性操作,才能保证使用volatile关键字的程序在并发时能够正确执行。
synchronized 与 lock
为什么要线程同步
java允许多线程并发控制,当多个线程同时操作一个可共享的资源变量时(如数据的增删改查), 将会导致数据不准确,相互之间产生冲突,因此加入同步锁以避免在该线程没有完成操作之前,被其他线程的调用,从而保证了该变量的唯一性和准确性。
Java中的每个对象都可以作为锁。
- 普通同步方法,锁是当前实例对象。
- 静态同步方法,锁是当前类的class对象。
- 同步代码块,锁是括号中的对象。
锁的类型
- 可重入锁:在执行对象中所有同步方法不用再次获得锁
- 可中断锁:在等待获取锁过程中可中断
- 公平锁: 按等待获取锁的线程的等待时间进行获取,等待时间长的具有优先获取锁权利
- 读写锁:对资源读取和写入的时候拆分为2部分处理,读的时候可以多线程一起读,写的时候必须同步地写
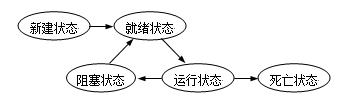
线程总共有5大状态,通过上面第二个知识点的介绍,理解起来就简单了。
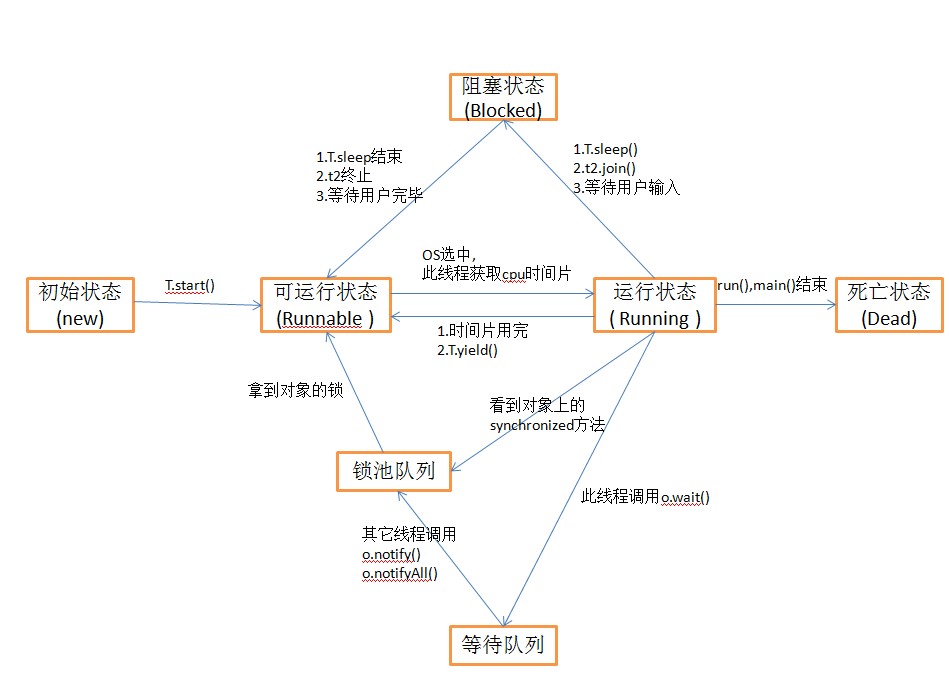
- 新建状态:新建线程对象,并没有调用start()方法之前
- 就绪状态:调用
start()方法之后线程就进入就绪状态,但是并不是说只要调用start()方法线程就马上变为当前线程,在变为当前线程之前都是为就绪状态。值得一提的是,线程在睡眠和挂起中恢复的时候也会进入就绪状态哦。 - 运行状态:线程被设置为当前线程,开始
执行run()方法。就是线程进入运行状态 - 阻塞状态:线程被暂停,比如说调用
sleep()方法后线程就进入阻塞状态 - 死亡状态:线程执行结束
Thread重要方法
- start()方法,调用该方法开始执行该线程;
- stop()方法,调用该方法强制结束该线程执行;
- join方法,调用该方法等待该线程结束。
- sleep()方法,调用该方法该线程进入等待。
- run()方法,调用该方法直接执行线程的run()方法,但是线程调用start()方法时也会运行run()方法,区别就是一个是由线程调度运行run()方法,一个是直接调用了线程中的run()方法!!
synchronized 与 lock的区别
| | synchronized|lock
-
存在层次 Java的关键字,在jvm层面上 是一个类 锁的释放 1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程释放锁 在finally中必须释放锁,不然容易造成线程死锁 锁的获取 假设A线程获得锁,B线程等待。如果A线程阻塞,B线程会一直等待 分情况而定,Lock有多个锁获取的方式,具体下面会说道,大致就是可以尝试获得锁,线程可以不用一直等待 锁状态 无法判断 可以判断 锁类型 可重入 不可中断 非公平 可重入 可判断 可公平(两者皆可) 性能 少量同步 大量同步 - Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离)
- 在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
- ReentrantLock提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。在资源竞争不激烈的情形下,性能稍微比synchronized差点点。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍。而ReentrantLock确还能维持常态。
小结:
- synchronized 在成功完成功能或者抛出异常时,虚拟机会自动释放线程占有的锁;而Lock对象在发生异常时,如果没有主动调用unLock()方法去释放锁,则锁对象会一直持有,因此使用Lock时需要在finally块中释放锁;
- lock接口锁可以通过多种方法来尝试获取锁包括立即返回是否成功的tryLock(),以及一直尝试获取的lock()方法和尝试等待指定时间长度获取的方法,相对灵活了许多比synchronized; 3). 通过在读多,写少的高并发情况下,我们用ReentrantReadWriteLock分别获取读锁和写锁来提高系统的性能,因为读锁是共享锁,即可以同时有多个线程读取共享资源,而写锁则保证了对共享资源的修改只能是单线程的。
Lock 接口源码
public interface Lock {
/**
* Acquires the lock.
*/
void lock();
/**
* Acquires the lock unless the current thread is
* {@linkplain Thread#interrupt interrupted}.
*/
void lockInterruptibly() throws InterruptedException;
/**
* Acquires the lock only if it is free at the time of invocation.
*/
boolean tryLock();
/**
* Acquires the lock if it is free within the given waiting time and the
* current thread has not been {@linkplain Thread#interrupt interrupted}.
*/
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
/**
* Releases the lock.
*/
void unlock();
}
主要方法:
- lock():获取锁,如果锁被暂用则一直等待
- unlock():释放锁
- tryLock(): 注意返回类型是boolean,如果获取锁的时候锁被占用就返回false,否则返回true
- tryLock(long time, TimeUnit unit):比起tryLock()就是给了一个时间期限,保证等待参数时间
- lockInterruptibly():用该锁的获得方式,如果线程在获取锁的阶段进入了等待,那么可以中断此线程,先去做别的事
底层实现
synchronized:我们知道java是用字节码指令来控制程序(这里不包括热点代码编译成机器码)。在字节指令中,存在有synchronized所包含的代码块,那么会形成2段流程的执行。
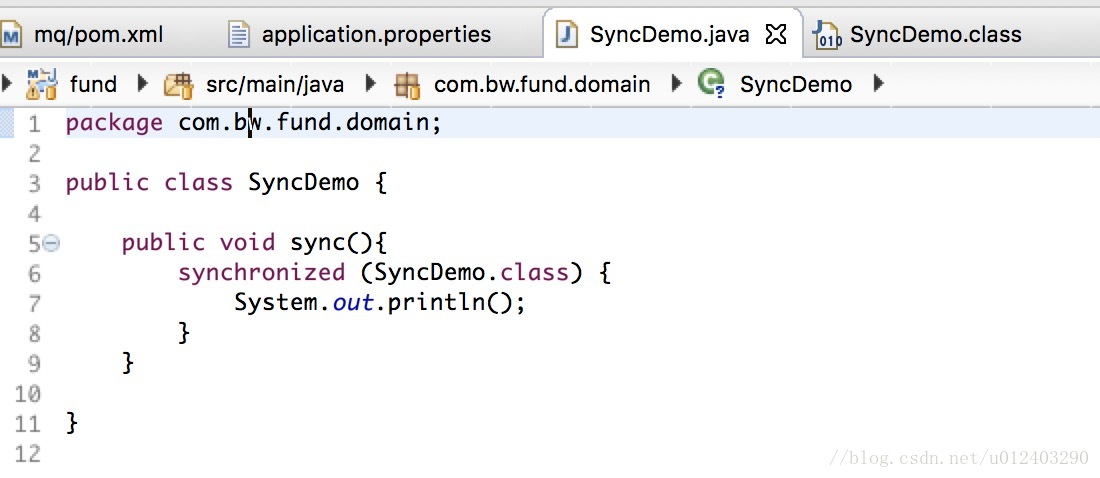
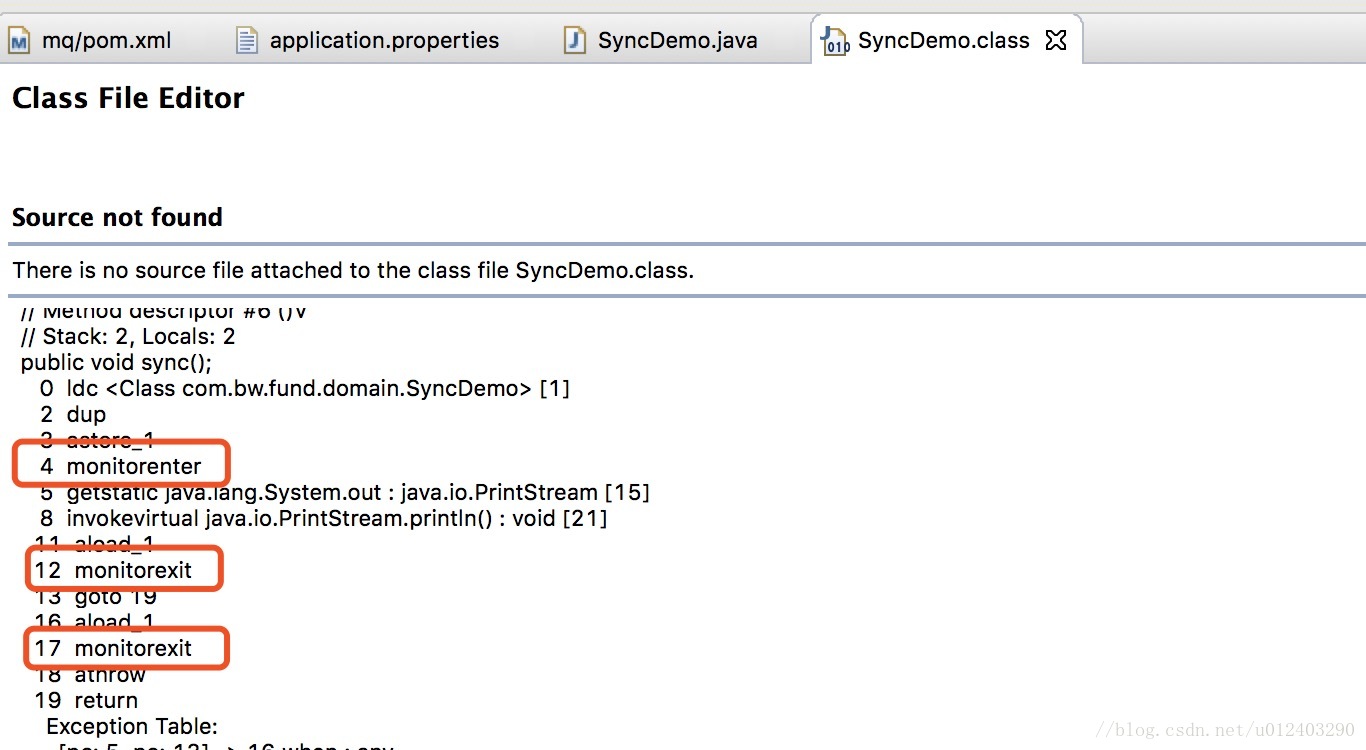
synchronized映射成字节码指令就是增加来两个指令:monitorenter和monitorexit。当一条线程进行执行的遇到monitorenter指令的时候,它会去尝试获得锁,如果获得锁那么锁计数+1(为什么会加一呢,因为它是一个可重入锁,所以需要用这个锁计数判断锁的情况),如果没有获得锁,那么阻塞。当它遇到monitorexit的时候,锁计数器-1,当计数器为0,那么就释放锁。
Lock- Lock实现和synchronized不一样,后者是一种
悲观锁,它胆子很小,它很怕有人和它抢吃的,所以它每次吃东西前都把自己关起来。而Lock呢底层其实是CAS乐观锁的体现,它无所谓,别人抢了它吃的,它重新去拿吃的就好啦,所以它很乐观。具体底层怎么实现,博主不在细述,有机会的话,我会对concurrent包下面的机制好好和大家说说,如果面试问起,你就说底层主要靠volatile和CAS操作实现的。
- Lock实现和synchronized不一样,后者是一种
无锁的执行者——CAS
CAS的全称是Compare And Swap 即比较交换,其算法核心思想如下
执行函数:CAS(V,E,N)
其包含3个参数:
- V表示要更新的变量
- E表示预期值
- N表示新值
如果V值等于E值,则将V的值设为N。若V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做。通俗的理解就是CAS操作需要我们提供一个期望值,当期望值与当前线程的变量值相同时,说明还没线程修改该值,当前线程可以进行修改,也就是执行CAS操作,但如果期望值与当前线程不符,则说明该值已被其他线程修改,此时不执行更新操作,但可以选择重新读取该变量再尝试再次修改该变量,也可以放弃操作,原理图如下
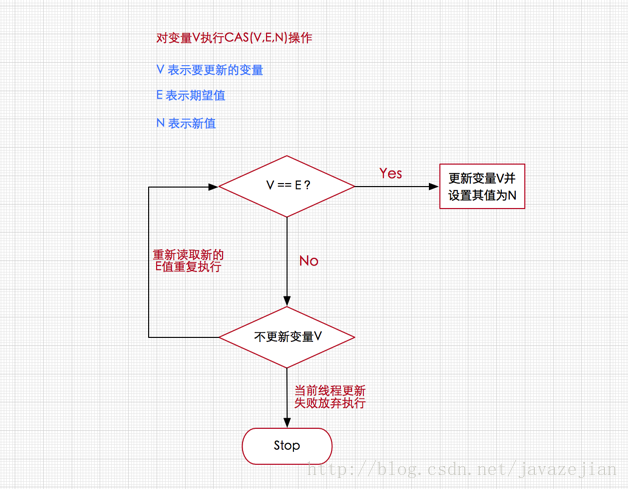
由于CAS操作属于乐观派,它总认为自己可以成功完成操作,当多个线程同时使用CAS操作一个变量时,只有一个会胜出,并成功更新,其余均会失败,但失败的线程并不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作,这点从图中也可以看出来。基于这样的原理,CAS操作即使没有锁,同样知道其他线程对共享资源操作影响,并执行相应的处理措施。同时从这点也可以看出,由于无锁操作中没有锁的存在,因此不可能出现死锁的情况,也就是说无锁操作天生免疫死锁。
JDK 1.6之后对Synchronized进行的优化
JDK1.6 之前,Synchronized是一个重量级锁:
- Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的。但是监视器锁本质又是依赖于底层的操作系统的Mutex Lock来实现的。而操作系统实现线程之间的切换这就需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么Synchronized效率低的原因。因此,这种依赖于操作系统Mutex Lock所实现的锁我们称之为
“重量级锁”。JDK中对Synchronized做的种种优化,其核心都是为了减少这种重量级锁的使用。
JDK1.6以后,为了减少获得锁和释放锁所带来的性能消耗,提高性能,增加了从偏向锁到轻量级锁再到重量级锁的过度。
- 锁的升级过程如下:锁的状态总共有四种:
无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁(但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级)

优化
1.自旋锁:为了减少线程状态改变带来的消耗 不停地执行当前线程。
自旋锁:
- 频繁的阻塞和唤醒对CPU来说是一件负担很重的工作,所谓自旋锁,就是让该线程等待一段时间,不会被立即挂起,看持有锁的线程是否会很快释放锁。怎么等待呢?
执行一段无意义的循环即可(自旋),如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好,反之,自旋的线程就会白白消耗掉处理的资源,它不会做任何有意义的工作,典型的占着茅坑不拉屎,这样反而会带来性能上的浪费。所以说,自旋等待的时间(自旋的次数)必须要有一个限度,如果自旋超过了定义的时间仍然没有获取到锁,则应该被挂起
适应性自旋锁
- JDK 1.6引入了更加聪明的自旋锁,即自适应自旋锁。所谓自适应就意味着自旋的次数不再是固定的,它是
由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。它怎么做呢?线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋能够成功的,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋过程,以免浪费处理器资源。 - 有了自适应自旋锁,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测会越来越准确,虚拟机会变得越来越聪明。
2.锁消除:锁消除是Java虚拟机在JIT编译是,通过对运行上下文的扫描,去除不可能存在共享资源竞争的锁,通过锁消除,可以节省毫无意义的请求锁时间。
- 锁消除即删除不必要的加锁操作。根据代码逃逸技术,如果判断到一段代码中,堆上的数据不会逃逸出当前线程,那么可以认为这段代码是线程安全的,不必要加锁。
- 例如:为了保证数据的完整性,我们在进行操作时需要对这部分操作进行同步控制,但是在有些情况下,JVM检测到不可能存在共享数据竞争,这是JVM会对这些同步锁进行锁消除(StringBuffer、Vector、HashTable的加锁操作)
public void vectorTest(){ Vector<String> vector = new Vector<String>(); for(int i = 0 ; i < 10 ; i++){ vector.add(i + ""); } System.out.println(vector); }
3.锁粗化:将连续的加锁 精简到只加一次锁。
package com.paddx.test.string;
public class StringBufferTest {
StringBuffer stringBuffer = new StringBuffer();
public void append(){
stringBuffer.append("a");
stringBuffer.append("b");
stringBuffer.append("c");
}
}
- 这里每次调用stringBuffer.append方法都需要加锁和解锁,如果虚拟机检测到有一系列连串的对同一个对象加锁和解锁操作,就会将其合并成一次范围更大的加锁和解锁操作,即在第一次append方法时进行加锁,最后一次append方法结束后进行解锁。
4.轻量级锁:无竞争条件下 通过CAS消除同步互斥(多个线程交替执行同步块,没有竞争)
轻量级锁并不是用来代替重量级锁的,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用产生的性能消耗。在解释轻量级锁的执行过程之前,先明白一点,轻量级锁所适应的场景是线程交替执行同步块的情况,如果存在同一时间访问同一锁的情况,就会导致轻量级锁膨胀为重量级锁。
轻量级锁的加锁过程
(1)在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,官方称之为 Displaced Mark Word。这时候线程堆栈与对象头的状态如图2.1所示。
(2)拷贝对象头中的Mark Word复制到锁记录中。
(3)拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock record里的owner指针指向object mark word。如果更新成功,则执行步骤(3),否则执行步骤(4)。
(4)如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,即表示此对象处于轻量级锁定状态,这时候线程堆栈与对象头的状态如图2.2所示。
(5)如果这个更新操作失败了,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。否则说明多个线程竞争锁,轻量级锁就要膨胀为重量级锁,锁标志的状态值变为“10”,Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。 而当前线程便尝试使用自旋来获取锁,自旋就是为了不让线程阻塞,而采用循环去获取锁的过程。
轻量级锁的解锁过程:
(1)通过CAS操作尝试把线程中复制的Displaced Mark Word对象替换当前的Mark Word。 (2)如果替换成功,整个同步过程就完成了。 (3)如果替换失败,说明有其他线程尝试过获取该锁(此时锁已膨胀),那就要在释放锁的同时,唤醒被挂起的线程。
5.偏向锁:(只有一个线程执行同步)无竞争条件下 消除整个同步互斥,连CAS都不操作。
引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令(由于一旦出现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗必须小于节省下来的CAS原子指令的性能消耗)。上面说过,轻量级锁是为了在线程交替执行同步块时提高性能,而偏向锁则是在只有一个线程执行同步块时进一步提高性能。
偏向锁获取过程:
(1)访问Mark Word中偏向锁的标识是否设置成1,锁标志位是否为01——确认为可偏向状态。
(2)如果为可偏向状态,则测试线程ID是否指向当前线程,如果是,进入步骤(5),否则进入步骤(3)。
(3)如果线程ID并未指向当前线程,则通过CAS操作竞争锁。如果竞争成功,则将Mark Word中线程ID设置为当前线程ID,然后执行(5);如果竞争失败,执行(4)。
(4)如果CAS获取偏向锁失败,则表示有竞争。当到达全局安全点(safepoint)时获得偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码。
(5)执行同步代码。
偏向锁的释放:
- 偏向锁的撤销在上述第四步骤中有提到。偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程不会主动去释放偏向锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行),它会首先暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态,撤销偏向锁后恢复到未锁定(标志位为“01”)或轻量级锁(标志位为“00”)的状态。
6.重量级锁
- 重量级锁的加锁、解锁过程和轻量级锁差不多,区别是:
竞争失败后,线程阻塞,释放锁后,唤醒阻塞的线程,不使用自旋锁,不会那么消耗CPU,所以重量级锁适合用在同步块执行时间长的情况下。
总结
- 本文重点介绍了JDk中采用轻量级锁和偏向锁等对Synchronized的优化,但是这两种锁也不是完全没缺点的,
比如竞争比较激烈的时候,不但无法提升效率,反而会降低效率,因为多了一个锁升级的过程,这个时候就需要通过-XX:-UseBiasedLocking来禁用偏向锁。下面是这几种锁的对比:
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距。 | 如果线程间存在锁竞争,会带来额外的锁撤销的消耗。 | 适用于只有一个线程访问同步块场景。 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度。 | 如果始终得不到锁竞争的线程使用自旋会消耗CPU。 | 追求响应时间。同步块执行速度非常快。 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗CPU。 | 线程阻塞,响应时间缓慢。 | 追求吞吐量。同步块执行时间较长。 |
String,StringBuilder,StringBuffer
这三个类之间的区别主要是在两个方面,即运行速度和线程安全这两方面。
运行速度
或者说是执行速度,在这方面运行速度快慢为:StringBuilder > StringBuffer > String
String最慢的原因:
- String的底层代码为一个用
final修饰的char数组,这意味着定义一个String变量以后,该变量的内容是不可变的。而StringBuilder 与StringBuffer都继承自AbstractStringBuilder,该类的char数组并没有用final修饰,内容是可变的 - String为
字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,但后两者的对象是变量,是可以更改的。以下面一段代码为例:
String str="abc";
System.out.println(str);
str=str+"de";
System.out.println(str);
如果运行这段代码会发现先输出“abc”,然后又输出“abcde”,好像是str这个对象被更改了,其实,这只是一种假象罢了,JVM对于这几行代码是这样处理的,首先创建一个String对象str,并把“abc”赋值给str,然后在第三行中,其实JVM又创建了一个新的对象也名为str,然后再把原来的str的值和“de”加起来再赋值给新的str,而原来的str就会被JVM的垃圾回收机制(GC)给回收掉了,所以,str实际上并没有被更改,也就是前面说的String对象一旦创建之后就不可更改了。所以,Java中对String对象进行的操作实际上是一个不断创建新的对象并且将旧的对象回收的一个过程,所以执行速度很慢。
而StringBuilder和StringBuffer的对象是变量,对变量进行操作就是直接对该对象进行更改,而不进行创建和回收的操作,所以速度要比String快很多。
另外,有时候我们会这样对字符串进行赋值
String str="abc"+"de";
StringBuilder stringBuilder=new StringBuilder().append("abc").append("de");
System.out.println(str);
System.out.println(stringBuilder.toString());
```
这样输出结果也是“abcde”和“abcde”,但是String的速度却比StringBuilder的反应速度要快很多,这是因为第1行中的操作和
```java
String str="abcde";
是完全一样的,所以会很快,而如果写成下面这种形式
String str1=”abc”; String str2=”de”; String str=str1+str2;
那么JVM就会像上面说的那样,不断的创建、回收对象来进行这个操作了。速度就会很慢。
线程安全
在线程安全上,StringBuilder是线程不安全的,而StringBuffer是线程安全的
如果一个StringBuffer对象在字符串缓冲区被多个线程使用时,StringBuffer中很多方法可以带有synchronized关键字,所以可以保证线程是安全的,但StringBuilder的方法则没有该关键字,所以不能保证线程安全,有可能会出现一些错误的操作。所以如果要进行的操作是多线程的,那么就要使用StringBuffer,但是在单线程的情况下,还是建议使用速度比较快的StringBuilder。
总结一下
String:适用于少量的字符串操作的情况StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
equals 和 ==
顺带提一下Object类中的equals()方法与运算符 == 的区别:
==
== 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象。比较的是真正意义上的指针操作。
- 比较的是操作符两端的操作数是否是同一个对象。
- 两边的操作数必须是同一类型的(可以是父子类之间)才能编译通过。
- 比较的是地址,如果
是具体的阿拉伯数字的比较,值相等则为true,如:int a=10 与 long b=10L 与 double c=10.0都是相同的(为true),因为他们都指向地址为10的堆。
equals
equals用来比较的是两个对象的内容是否相等,由于所有的类都是继承自java.lang.Object类的,所以适用于所有对象,如果没有对该方法进行覆盖的话,调用的仍然是Object类中的方法,而Object中的equals方法返回的却是==的判断。可以看Object类中equals()方法的源码:
public boolean equals(Object obj) {
return (this == obj);
}
String s=”abce”是一种非常特殊的形式,和new 有本质的区别。它是java中唯一不需要new 就可以产生对象的途径。以 String s=”abce” 形式赋值在java中叫直接量,它是在常量池中而不是象new一样放在压缩堆中。这种形式的字符串,在JVM内部发生字符串拘留,即当声明这样的一个字符串后,JVM会在常量池中先查找有有没有一个值为"abcd"的对象,如果有,就会把它赋给当前引用。即原来那个引用和现在这个引用指点向了同一对象,如果没有,则在常量池中新创建一个”abcd”,下一次如果有String s1 = “abcd”;又会将s1指向”abcd”这个对象,即以这形式声明的字符串,只要值相等,任何多个引用都指向同一对象。
而String s = new String(“abcd”);和其它任何对象一样,每调用一次就产生一个对象,只要它们调用。
也可以这么理解: String str1 = “hello”; 先在内存中找是不是有”hello”这个对象,如果有,就让str指向那个”hello”.如果内存里没有”hello”,就创建一个新的对象保存”hello”. String str2=new String (“hello”) 就是不管内存里是不是已经有"hello"这个对象,都新建一个对象保存"hello"。
那么此时内存中有两个hello对象,如果这时使用 String str3 = “hello”; 引用的会是 str1还是str2呢?验证一下:
public class Main {
public static void main(String[] args) {
String str1 = "hello";
String str1_1 = "hello";
System.out.println("str1 == str1_1 ? " + (str1 == str1_1));
String str2 = new String("hello");
System.out.println("str2 == str1 ? " + (str2 == str1));
String str3 = "hello";
System.out.println("str3 == str1 ? " + (str3 == str1));
System.out.println("str3 == str2 ? " + (str3 == str2));
System.out.println("str3.equals(str2) ? " + str3.equals(str2));
}
}
结果显示,str3 == str1 != str2 对于在常量池中同值的多个对象,是按最先创建的那个去给新的引用分配的。
下面详细讨论String的比较问题 ↓
String 比较
前面理解了String 类型的底层实现原理,知道了String的底层代码是一个用final修饰的char数组实现的。所以对于String的字符串对象,其值是存储在常量池中的。那么对于字符串的比较就有可以探究的东西了。
比较1:使用 ==
public class StringDemo01{
public static void main(String args[]){
String str1 = "hello" ; // 直接赋值
String str2 = new String("hello") ; // 通过new赋值
String str3 = str2 ; // 传递引用
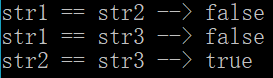
System.out.println("str1 == str2 --> " + (str1==str2)) ; // false
System.out.println("str1 == str3 --> " + (str1==str3)) ; // false
System.out.println("str2 == str3 --> " + (str2==str3)) ; // true
}
};
分析:
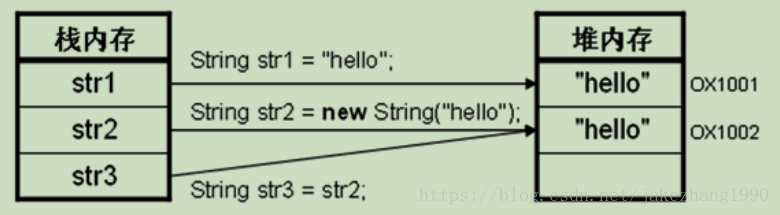
这里简单的就认为内容开辟在了堆内存中了,这个堆可以理解为广义上的用来保存内容的内存区域,栈内存可以简单认为是用来保存引用的内存地址。具体的内存地址划分,牵扯太多,就不深入说了。(其实这String的内容是保存在常量池的)
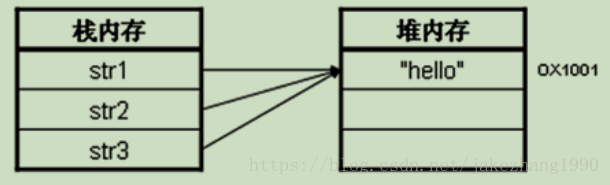
因为String的值存储在常量池中,所以不论申明再多的String对象,只要其值相同,这些对象指向的都是同一个内存地址
public class StringDemo04{
public static void main(String args[]){
String str1 = "hello" ; // 直接赋值
String str2 = "hello" ; // 直接赋值
String str3 = "hello" ; // 直接赋值
System.out.println("str1 == str2 --> " + (str1==str2)) ; // true
System.out.println("str1 == str3 --> " + (str1==str3)) ; // true
System.out.println("str2 == str3 --> " + (str2==str3)) ; // true
}
};
比较2:使用equals()
public class StringDemo02{
public static void main(String args[]){
String str1 = "hello" ; // 直接赋值
String str2 = new String("hello") ; // 通过new赋值
String str3 = str2 ; // 传递引用
System.out.println("str1 equals str2 --> " + (str1.equals(str2))) ; // true
System.out.println("str1 equals str3 --> " + (str1.equals(str3))) ; // true
System.out.println("str2 equals str3 --> " + (str2.equals(str3))) ; // true
}
};
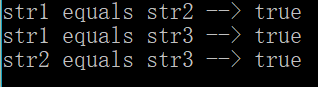
原因:“==”判断的是地址值,equals()方法判断的是内容。
public class StringDemo03{
public static void main(String args[]){
String str1 = "hello" ; // 直接赋值
String str2 = new String("hello") ; // 通过new赋值
String str3 = str2 ; // 传递引用
System.out.println("str1-hashCode == str2-hashCode --> " + (str1.hashCode()==str2.hashCode())) ; // false
System.out.println("str1-hashCode == str3-hashCode --> " + (str1.hashCode()==str3.hashCode())) ; // false
System.out.println("str2-hashCode == str3-hashCode --> " + (str2.hashCode()==str3.hashCode())) ; // true
}
}

看到hashCode是一样的,hashCode相同可能是同一个对象,也可能是不同的对象,但是hashCode不同就肯定是不同的对象。
- 如果两个对象equals相等,那么这两个对象的HashCode一定也相同
- 如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象
在散列存储结构中,存放于同一个位置
访问控制修饰符
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
default(即缺省,什么也不写): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。private: 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)public: 对所有类可见。使用对象:类、接口、变量、方法protected: 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
默认访问修饰符-不使用任何关键字
使用默认访问修饰符声明的变量和方法,对同一个包内的类是可见的。接口里的变量都隐式声明为 public static final,而接口里的方法默认情况下访问权限为 public。
私有访问修饰符-private
私有访问修饰符是最严格的访问级别,所以被声明为 private 的方法、变量和构造方法只能被所属类访问,并且类和接口不能声明为 private。
声明为私有访问类型的变量只能通过类中公共的 getter 方法被外部类访问。
Private 访问修饰符的使用主要用来隐藏类的实现细节和保护类的数据。
公有访问修饰符-public
被声明为 public 的类、方法、构造方法和接口能够被任何其他类访问。
如果几个相互访问的 public 类分布在不同的包中,则需要导入相应 public 类所在的包。由于类的继承性,类所有的公有方法和变量都能被其子类继承。
受保护的访问修饰符-protected
protected 需要从以下两个点来分析说明:
- 子类与基类在同一包中:被声明为 protected 的变量、方法和构造器能被同一个包中的任何其他类访问;
- 子类与基类不在同一包中:那么在子类中,子类实例可以访问其从基类继承而来的 protected 方法,而不能访问基类实例的protected方法。
protected 可以修饰数据成员,构造方法,方法成员,不能修饰类(内部类除外)。
Java8新特性default关键字
Java在创立之初就摒弃了C++多继承的套路,因为它实在难以学习与使用,在Java的世界中类只能继承一个父类,但是一个接口可以继承多个接口。
default关键字的意义:default关键字的意义,default的意思就是为接口方法提供默认的实现,它的最终目的就是减少子类实现接口的工作量,如果多个子类实现的某个接口方法,方法体都是一样的,这就会导致后期维护上的困难,如果在接口中定义默认的实现,那么既减少了子类实现的接口的工作量,也为后期的维护提供了方便(只需要更改接口中的默认实现即可)。
大家都知道Java中的接口都是抽象方法,也就是没有方法体,但是从Java8开始,如果接口中的方法被default关键字修饰后就必须为其加上方法体。某个类在实现该接口时,就不会强制实现被default修饰的方法,因为在接口中已经写好了方法体。从Java8开始,接口就开始类似于抽象类了,它们都可以含有普通方法和抽象方法了,唯一不同的就是一个类只能继承一个抽象类,而一个类却能实现多个接口。
因为default导致的 多继承问题的引入
问题引入:现有两个接口,A和B,这两个接口都有一个方法sayHello,并且都使用default关键字修饰后使其拥有了方法体,但是现在有接口C需要同时继承A,B,代码如下:
public interface A {
default void sayHello(){
System.out.print("A.Hello");
}
}
public interface B {
default void sayHello(){
System.out.print("B.Hello");
}
}
public interface C extends A,B{
}
此时多继承的问题就展现出来了,到底C接口是继承A接口的sayHello方法,还是继承B接口的sayHello方法,这也就是Java多继承的源头,允许接口有方法体,并且接口之间可以多继承。(上面代码由于有多继承问题,编译会报错!!)
解决:Java给出的解决方案就是:在出现多继承问题的时候必须手动覆写冲突方法,这种方式可谓是简单粗暴,但很好理解。手动覆写后编译器就不纠结到底继承哪个父类的方法了,也就解决了多继承问题。
子接口在手动覆写父接口方法时可以手动调用冲突方法,调用格式如下:
public interface A {
default void sayHello(){
System.out.print("A.Hello");
}
}
public interface B {
default void sayHello(){
System.out.print("B.Hello");
}
}
public interface C extends A,B{
@Override
default void sayHello() {
A.super.sayHello();
}
}
public class Test impements A.B {//类的多实现本质上就是多继承
@Override
default void sayHello() {//因为接口A和接口B中的默认方法冲突,所以必须手动实现sayHello方法
A.super.sayHello();
}
}
Java注解——Annotation
从JDK5开始,Java增加对元数据的支持,也就是注解,注解与注释是有一定区别的,可以把注解理解为代码里的特殊标记,这些标记可以在编译,类加载,运行时被读取,并执行相应的处理。通过注解开发人员可以在不改变原有代码和逻辑的情况下在源代码中嵌入补充信息。
注解分类
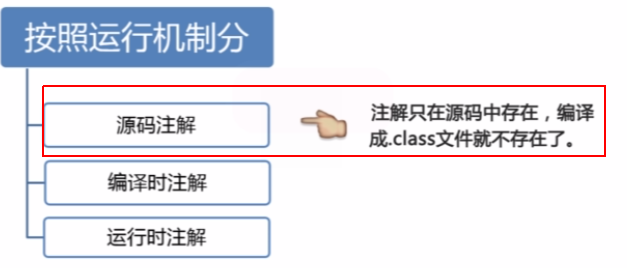
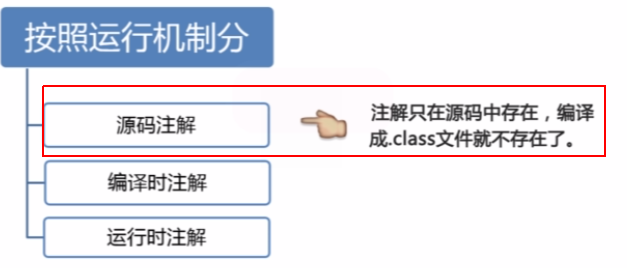
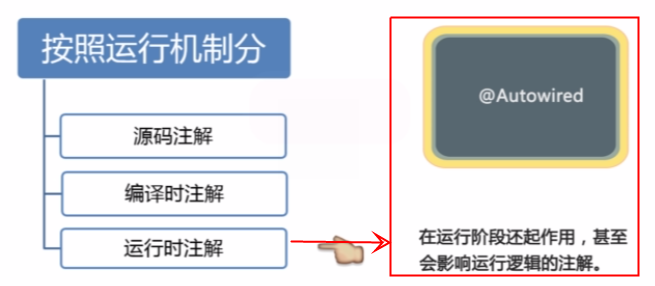
按照来源来分的话,有如下三类:
- JDK自带的注解(Java目前只内置了三种
标准注解:@Override、@Deprecated、@SuppressWarnings,以及四种元注解:@Target、@Retention、@Documented、@Inherited) - 第三方的注解——这一类注解是我们接触最多和作用最大的一类
- 自定义注解——也可以看作是我们编写的注解,其他的都是他人编写注解
JDK 标准注解
想像代码具有生命,注解就是对于代码中某些鲜活个体的贴上去的一张标签。简化来讲,注解如同一张标签。
@Override 表示覆盖或重写父类的方法;
@Deprecated 表示该方法已经过时了。(当方法或是类上面有@Deprecated注解时,说明该方法或是类都已经过期不能再用,但不影响以前项目使用,提醒你新替代待的方法或是类。如果程序员不小心使用了它的元素,那么编译器会发出警告信息。)
@SuppressWarnings 表示忽略指定警告,比如@Suppvisewarnings(“Deprecation”)
元注解

@Target 是注解的作用域 :表示该注解可以用于一个类中的那些属性及方法上,如果作用域类型有多个用英文逗号分隔
@Retention:表示该注解的生命周期
@Inherited:此注解是标识性的元注解,表示当前注解可以由子注解来继承
@Documented:表示生成javadoc的时候会包含注解
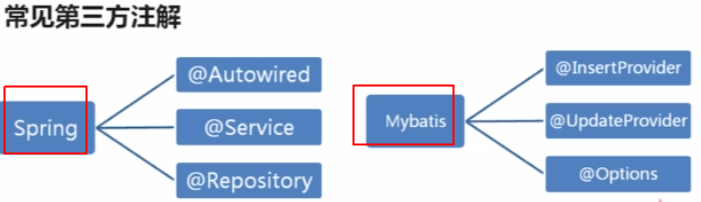
第三方注解
自定义注解


注解的定义看起来很像接口的定义,事实上,与其他任何Java接口一样,注解也将会编译成class文件。
定义注解时,会需要一些元注解(meta-annotation),如@Target和@Retention。@Target用来定义你的注解将用于什么地方(例如是一个方法或一个域)。@Retention用来定义该注解在哪一个级别可用,在源代码(SOURCE)、类文件中(CLASS)或者运行时(RUNTIME)
示例:

解析注解
通过反射获取类、函数或成员上运行时注解信息,从而实现动态控制程序运行的逻辑。
如:

使用forName()方法加载类,并使用getAnnotation(Description.class)检查该类是否带有@Description注解。
注解的继承只能作用在类上,方法上的注解不会被继承,Interface中的所有注解不会被继承。
