算法设计与分析期末项目
Capacitated Facility Location Problem
问题描述
- 我们需要给m个消费者选择设备(facility)来满足每一个消费者的需求(demand)
- 每个设备都有他的容量(capacity)与打开设备时的开销(Opening Cost)
- 每个消费者都有他的需求(demand)与分配给每个设备时对应的开销(Assignment Cost)
- 对某个设备总的demand不能超出容量
- 我们需要寻找到总开销(Opening Cost +Assignment Cost)最少的分配方案,让每一个消费者的需求都得到满足。
解决此题的算法
贪心算法 (Greedy Algorithm)
- 对每一个消费者,都选择他当前可以选择的设备中(即该设备的capacity要大于该消费者的demand)开销最小的设备,是一种基本的贪心策略。
模拟退火算法 (SA)
- 模拟退火算法的出发点是基于物理中固体物质的退火过程与一般组合优化问题之间的相似性。模拟退火算法从某一较高初温出发,伴随温度参数的不断下降,结合概率突跳特性在解空间中随机寻找目标函数的全局最优解,即在局部最优解能概率性地跳出并最终趋于全局最优。
- 是迭代求解策略的一种随机寻优算法,模拟退火算法是一种通用的优化算法,理论上算法具有概率的全局优化性能。
- 是一种牺牲时间来换取精度的随机搜索算法。
遗传算法 (GA)
- 通过模拟自然进化的过程来搜索最优解。
- 同SA,也是一种牺牲时间来换取精度的随机搜索算法,他俩的差异在实验感想中我有总结。
实验过程
1.数据读取与处理:
实验提供的数据存放在instance文件夹中,我们需要对数据进行预处理,转换成我们所需要的形式。
- 分析数据可以得知,每一个实例的第一行分别为
设备数量n与消费者的数量m。 - 第二行开始的n行,每一行都只有两个数据,第一个是设备的容量capacity,第二个是设备的打开的开销Opening Cost。
- 剩下的数据,前面的 m 个数据,代表着每一个消费者的需求demand。
- 剩下的所有数据,每 n 个数据为一组,代表着一个消费者到所有设备的分配开销 Assignment Cost。
本次实验我用的语言为java,处理文件的函数我写好了一个decodeFile函数在mian.java中,用于解析文件。
- 在读通每个实例的数据含义之后,解析文件的思路就变得比较清晰了,我使用了两个三维数组来存储每一个实例解析获得的所有facility的数据和所有customer的数据。
private static int[][][] facility = new int[71][][]; private static int[][][] customer = new int[71][][];//封装好用于解析文件 public static void decodeFile(File file,int i){ List<Integer> integers = new ArrayList<>(); Scanner sc = null; try { sc = new Scanner(file); } catch (FileNotFoundException e) { e.printStackTrace(); } int facilityCount = sc.nextInt(); int customerCount = sc.nextInt(); int count = 0; int size = facilityCount * 2; int doubleSize = customerCount * (facilityCount + 1); while (count < size + doubleSize) { count++; integers.add((int) sc.nextDouble()); } facility[i] = new int[facilityCount][2]; customer[i] = new int[customerCount][facilityCount + 1]; int temp = 0; for (int j = 0; j < facilityCount * 2; j++) { facility[i][j / 2][j % 2] = integers.get(j); temp = j; } temp++; for (int j = temp; j < temp + customerCount; j++) { customer[i][j - temp][0] = integers.get(j); } temp = temp + customerCount; for (int j = temp; j < integers.size(); j++) { customer[i][(j - temp) / facilityCount][(j - temp) % facilityCount + 1] = integers.get(j); } }
2. 贪心算法:
- 从第一个消费者开始,遍历所有的设备,选择其中的分配开销最低且所剩容量满足本消费者的需求的仓库。
- 总共只需要两个循环,由于本次实验所使用的数据量最多的案例也不过6000多个,所以这样贪心的解决方式所消耗的时间是非常少的,在1ms左右便可以遍历出贪心的结果。
- 计算开销的方式:不论设备是否打开过,都优先选择分配开销最低的设备,总的开销最后再看设备是否已经打开再来添上打开的开销。
//贪心算法,优先选择当前满足要求的facility中cost最小的。 public GreedyResult Greedy(int[][] facilities, int[][] customers){ this.facilities = facilities; this.customers = customers; facilitiesCount = facilities.length; customersCount = customers.length; int[][] tempFacilities = copyFacility(); int[] facilitiesStatus = new int[tempFacilities.length]; int[] customersToFacilities = new int[customers.length]; long startTime=System.currentTimeMillis(); int costSum = 0; for(int i = 0;i<customers.length;i++){ int minCost = 99999; int selectIndex = -1; for(int j =0;j<tempFacilities.length;j++){ int currentCost = 0; //facility的capacity需要大于当前customer的需求 if(tempFacilities[j][0]<customers[i][0]){ continue; } currentCost += customers[i][j+1]; if(currentCost <= minCost){ minCost = currentCost; selectIndex = j; } } if(facilitiesStatus[selectIndex] == 0){ facilitiesStatus[selectIndex] = 1; costSum += tempFacilities[selectIndex][1]; } customersToFacilities[i] = selectIndex; tempFacilities[selectIndex][0] -= customers[i][0]; costSum += minCost; } ··· ··· long endTime=System.currentTimeMillis(); GreedyResult greedyResult = new GreedyResult(endTime-startTime,facilitiesStatus,customersToFacilities,costSum); return greedyResult; }3.模拟退火
初温——我的初温设为150。初温设置的高低影响的是对差解的接受率,因为模拟退火算法是以概率exp(-ΔT/T)接受差的新解的,若初温太高容易把好的解也给跳出了,太低又容易导致卡在局部最优;由于我初始解产生是通过贪心生成的,所以初温设为150,如果我使用的是另外一种方案即用随机来生成初始解,初温则可以调高一些。初始解状态S(算法迭代的起点)——初始解我试过两种生成方式,一是生成一个随机的合理的解。(不合理即某一工厂的capacity小于所有选择该工厂的消费者的demand之和)for(int i=1;i<customersCount;i++){ int[][] tempFacilities1 = copyFacility(); for(int j=0;j<customersCount;j++){ Random r = new Random(); int s = r.nextInt(facilitiesCount); while (tempFacilities1[s][0] < customers[j][0]){ s = (s+1)%facilitiesCount; } tempFacilities1[s][0] -= customers[j][0]; initList.add(s); } }- 也可以使用贪心算法产生的解来作为初始解。
//使用贪心算法来求初值 GreedyAlgorithm greedy = new GreedyAlgorithm(); GreedyResult greedyResult = greedy.Greedy(facilities,customers); List<Integer> initList = new ArrayList<>(); for(int i=0;i<greedyResult.customersToFacilities.length;i++){ initList.add(greedyResult.customersToFacilities[i]); } - 最后对比选择贪心生成初始解。
- 也可以使用贪心算法产生的解来作为初始解。
每个T值的迭代次数L——设为200产生新解S′——我产生新解的方式有两种:- 随机交换解中某两个位置的值;
- 随机改变解中某一位置的值;
- 当然,这两种方法产生的新解肯定是
合理的。通过比较可以发现,第一种产生新解的方式,不论迭代次数增加多少,都是很容易卡在局部最优解,这样出来的结果比GA还差,是不好的;而第二种产生新解的方式,让新解的“扰动作用”大大增加,即可以选择其他消费者都没有选择过的设备,更容易跳出局部最优解。且没有第一种方式的交换操作,耗时更短。
评价函数 calCost——计算该解的总开销,来评判解的优劣,若新解的cost < 旧解的cost,则把新解接受为新的当前解;若新解的cost > 旧解的cost,则以概率exp(-ΔT/T)接受S′作为新的当前解,这个概率就是SA算法跳出局部最优解的关键所在。降温系数——每次退火时降温的系数,T *= (降温系数),指数下降至温度下界EPS温度下界EPS——温度退到下界时,算法终止。while (Temperature > EPS){ int count = 0;// 迭代次数 while (count < Iteration){ List<Integer> tempList = new ArrayList<>(); tempList.addAll(initList); qwer++; count++; Random r = new Random(); int newResult = INVALID; int oldResult = costCurrent; while (newResult == INVALID){ //随机产生新解 int n = r.nextInt(customersCount); int m = r.nextInt(facilitiesCount); //领域操作——随机变换一个新的设备选择 tempList.set(n,m); newResult = calCost(tempList); } //以1的概率接受新解 if(newResult < oldResult){ initList.clear(); initList.addAll(tempList); costCurrent = newResult; } //以exp(-ΔT/T)接受新解,用以跳出局部最优 else if(accessProbability < Math.exp((oldResult - newResult) / Temperature)){ initList.clear(); initList.addAll(tempList); costCurrent = newResult; } } Temperature *= coolingCoefficient; }
4.遗传算法
编码——编码我的思路是把每一个消费者选择的设备序号所组成的List,作为遗传编码来使用。个体——上述的每一个序列产生的编码即定义的一个个体,而每一个个体有他们的适应值,所有的个体组成了种群。适应值函数——即为一个解码过程:calFitness,通过 calCost 函数算出所有个体的开销,而适应值即为种群所有个体中最大的开销减去当前每一个个体的开销,这样,开销越低的个体适应值越高,越能存活下去,便于后面轮盘赌来进行选择。同时,每一次的适应值在种群发生变化时都可能会改变,需在种群改变时重新计算。//计算个体的cost int calCost(List<Integer> individualSpecies){ int fitness = 0; int[] facilitiesStatus = new int[facilitiesCount]; int[][] tempFacilities = copyFacility(); for (int i=0;i<customersCount;i++){ int toWhichFacility = individualSpecies.get(i); //如果出了坏种(facility的capacity超出了),给其添上惩罚值 if(tempFacilities[toWhichFacility][0] < 0){ return INVALID; } if(facilitiesStatus[toWhichFacility] == 0){ facilitiesStatus[toWhichFacility] = 1; fitness += tempFacilities[toWhichFacility][1]; } fitness += customers[i][toWhichFacility+1]; tempFacilities[toWhichFacility][0] -= customers[i][0]; } return fitness; } //计算所有的个体适应值——计算每一个个体的fitness = cost(max) - cost(currentIndividual) void calAllFitness(){ AllFitness.clear(); int maxCost = AllCost.get(0); for(int i=0;i<AllCost.size();i++){ if(AllCost.get(i)>maxCost) maxCost = AllCost.get(i); } for(int i=0;i<AllCost.size();i++){ AllFitness.add(maxCost-AllCost.get(i)); } }遗传操作——选择、交叉与变异。对应着生物种群的自然选择与遗传变异。选择:按照每个个体的适应值,使用轮盘赌的方法,来随机选择个体加入到交配池中。每一个个体被选择的概率为fitness(i)/fitnessSum。不过为了加快算法收敛的速度,我每次选择都复制一份适应值最大的个体到繁殖池中,这样可以加快算法收敛的速度。//选择 private void select(List<List<Integer>> species){ List<List<Integer>> newSpecies = new ArrayList<>(); int bestIndex = getBest(AllCost); AllCost.clear(); //复制最好个体talentNum次 for(int i=0;i<talentNum;i++){ newSpecies.add(species.get(bestIndex)); AllCost.add(calCost(species.get(bestIndex))); } int fitnessSum = 0;//求出所有适应值之和 for(int i=0;i<AllFitness.size();i++){ fitnessSum += AllFitness.get(i); } int selectNum = species.size() - talentNum; //轮盘赌选择个体species.size() - talentNum次 for(int i=0;i<selectNum;i++){ int currentFitness = 0; //在0-fitnessSum之间产生一个随机数,用于轮盘赌选择个体 Random r = new Random(); int s; if(fitnessSum == 0) s = 0; else s = r.nextInt(fitnessSum); int index = 0; while (currentFitness<s){ currentFitness += AllFitness.get(index); if(currentFitness > s) break; index++; } newSpecies.add(species.get(index)); AllCost.add(calCost(species.get(index))); } species.clear(); species.addAll(newSpecies);//新种群替换掉原种群 calAllFitness();//重新计算所有的适应值 }交叉:选择出来交配池之后,自然要进行交配产生新的后代,交配的方法很简单,在交叉率(crossProbability)的前提下,概率地选择交配池中两个个体,然后在随机的位置 i 上,把两个父个体 i 位置后的编码进行交换即产生两个后代个体,同样的,为了加快算法的收敛,我在生成的两个个体加入到下一代种群之前,先判断其编码是否合理(即对应选择的设备中有没有demand已经超出了capacity的情况),不合理的直接淘汰,不加入到下一代种群中,留下他的父个体;合理便将其加入到下一代的种群里。- 生成的个体是否合理,在计算该个体开销的calCost函数中便可以判断,如果个体不合理,便为其添加一个惩罚值,让其无法在种群中生存下去。
//交叉 private void cross(List<List<Integer>> species){ int q=0; List<List<Integer>> nextGeneration = new ArrayList<>(); List<Integer> nextGenerationCost = new ArrayList<>(); while (q<species.size() && q+1<species.size()){ Random rand=new Random(); float rFloat = rand.nextFloat(); //交叉率 if(rFloat < crossProbability){ //在序列上随机取一个位置交叉 int crossIndex=rand.nextInt(customersCount-1); List<Integer> offspring1 = new ArrayList<>(); List<Integer> offspring2 = new ArrayList<>(); List<Integer> parent1 = species.get(q); List<Integer> parent2 = species.get(q+1); for(int i=0;i<crossIndex;i++){ offspring1.add(parent1.get(i)); offspring2.add(parent2.get(i)); } for(int i=crossIndex;i<customersCount;i++){ offspring1.add(parent2.get(i)); offspring2.add(parent1.get(i)); } if(calCost(offspring1)!=INVALID){ nextGeneration.add(offspring1); nextGenerationCost.add(calCost(offspring1)); } else { nextGeneration.add(parent1); nextGenerationCost.add(calCost(parent1)); } if(calCost(offspring2)!=INVALID){ nextGeneration.add(offspring2); nextGenerationCost.add(calCost(offspring2)); } else { nextGeneration.add(parent2); nextGenerationCost.add(calCost(parent2)); } } else { nextGeneration.add(species.get(q)); nextGenerationCost.add(AllCost.get(q)); nextGeneration.add(species.get(q+1)); nextGenerationCost.add(AllCost.get(q+1)); } q+=2; } species.clear(); species.addAll(nextGeneration); AllCost.clear(); AllCost.addAll(nextGenerationCost); calAllFitness(); }
- 生成的个体是否合理,在计算该个体开销的calCost函数中便可以判断,如果个体不合理,便为其添加一个惩罚值,让其无法在种群中生存下去。
变异:为什么要有变异操作呢?如果没有变异操作,遗传算法的结果很可能卡在局部最优解,不论怎么交叉选择,有可能都跳不出这个局部最优解,从而影响了全局最优解的搜索。加入变异便给每一代种群都添加了一个随机性,为算法添加一个扰动作用。随机的生成一个新的个体,而这个个体很可能就是“拯救整个种群的人”,变异的合理结果添加到下一代种群里,这样使算法可以跳出局部最优,转而向全局最优搜索。- 按照变异概率,每一个个体都可以等概率的变异,而我的变异方式是:把变异概率下发生变异的个体,随机地选取他的编码的两个下标,然后把下标间的所有元素交换位置,实现变异的效果,同样的,变异的个体如果是不合理的(同交叉的结果一样),那么便不会加入到下一代种群中。
//变异 private void mutate(List<List<Integer>> species){ int i=0; //每个物种都可变异 while (i<species.size()) { float rate=(float)Math.random(); List<Integer> mutateOffspring = new ArrayList<>(); if (rate < mutationProbability) { //寻找逆转左右端点 Random rand = new Random(); int left = rand.nextInt(customersCount); int right = rand.nextInt(customersCount); while (left == right) { left = rand.nextInt(customersCount); right = rand.nextInt(customersCount); } if (left > right) { int temp; temp = left; left = right; right = temp; } List<Integer> offspring = species.get(i); //逆转left-right的下标元素 while (left < right) { int temp = offspring.get(left); offspring.set(left,offspring.get(right)); offspring.set(right,temp); left++; right--; } mutateOffspring = offspring; //变异出错误的个体直接淘汰 //变异好的个体添加进种群,然后淘汰最差的个体,这样的收敛会快很多 if (calCost(mutateOffspring) != 888888) { species.add(mutateOffspring); AllCost.add(calCost(mutateOffspring)); calAllFitness(); eliminateWorstIndividual(); } } i++; } calAllFitness(); }
- 按照变异概率,每一个个体都可以等概率的变异,而我的变异方式是:把变异概率下发生变异的个体,随机地选取他的编码的两个下标,然后把下标间的所有元素交换位置,实现变异的效果,同样的,变异的个体如果是不合理的(同交叉的结果一样),那么便不会加入到下一代种群中。
初始化种群——做遗传离不开种群,我们也需要定义一个原始种群(初代)来进行遗传操作。- 我的初始化种群的方式:利用前面的贪心算法,求出一个贪心的个体,可以理解为本种群的“王”,然后再通过随机的方式生成其他的后代个体,随机产生编码的方式也有限制,不能有无法生存的个体留在种群中,即始终不能让消费者对某个设备的总需求超过该设备facility的容量。
//随机生成初始种群,坏的个体舍去,重新生成 private void createBeginningSpecies(){ GreedyAlgorithm greedy = new GreedyAlgorithm(); GreedyResult greedyResult = greedy.Greedy(facilities,customers); List<Integer> greedyR = new ArrayList<>(); for(int i=0;i<greedyResult.customersToFacilities.length;i++){ greedyR.add(greedyResult.customersToFacilities[i]); } species.add(greedyR); for(int i=1;i<initSpeciesNum;i++){ int[][] tempFacilities = copyFacility(); List<Integer> createIndividual = new ArrayList<>(); for(int j=0;j<customersCount;j++){ Random r = new Random(); int s = r.nextInt(facilitiesCount); while (tempFacilities[s][0] < customers[j][0]){ s = (s+1)%facilitiesCount; } tempFacilities[s][0] -= customers[j][0]; createIndividual.add(s); } species.add(createIndividual); AllCost.add(calCost(createIndividual)); } //更新适应值表AllFitness calAllFitness(); }
- 我的初始化种群的方式:利用前面的贪心算法,求出一个贪心的个体,可以理解为本种群的“王”,然后再通过随机的方式生成其他的后代个体,随机产生编码的方式也有限制,不能有无法生存的个体留在种群中,即始终不能让消费者对某个设备的总需求超过该设备facility的容量。
控制参数的选取- 编码的长度——即消费者个数
- 种群规模——200
- 交叉概率——设为1,即每一代每个个体都有其交配的对象来产生下一代种群
- 变异概率——设为0.1,变异概率大,可以让算法收敛更快,但是过大容易让局部最优个体变异为适应值更低的个体,即容易把好的个体也变异掉,最终求出的最好的个体反而适应值低。
- 交叉概率——设为0.9,按90%的概率对繁衍池的每一对进行概率交叉。
- 繁衍代数——1000,代数高,更容易找到更优解,但是对应耗时增加。
- 惩罚值——设为888888,针对产生的不合理的个体,即不能在种群存活下去的个体。
数据结构
本次实验定义两个数据结构GreedyResult、GAResult,分别用于获取算法的结果,给主函数输出Result Table,Result类用于最终输出csv文件。
public class GreedyResult {
long time;
int[] facilitiesStatus;
int[] customersToFacilities;
int cost;
public GreedyResult(long time,int[] facilitiesStatus, int[] customersToFacilities, int cost){
this.cost = cost;
this.customersToFacilities = customersToFacilities;
this.facilitiesStatus = facilitiesStatus;
this.time = time;
}
}
实验结果
1. 贪心算法
-
Result Table:

-
Detail solution:
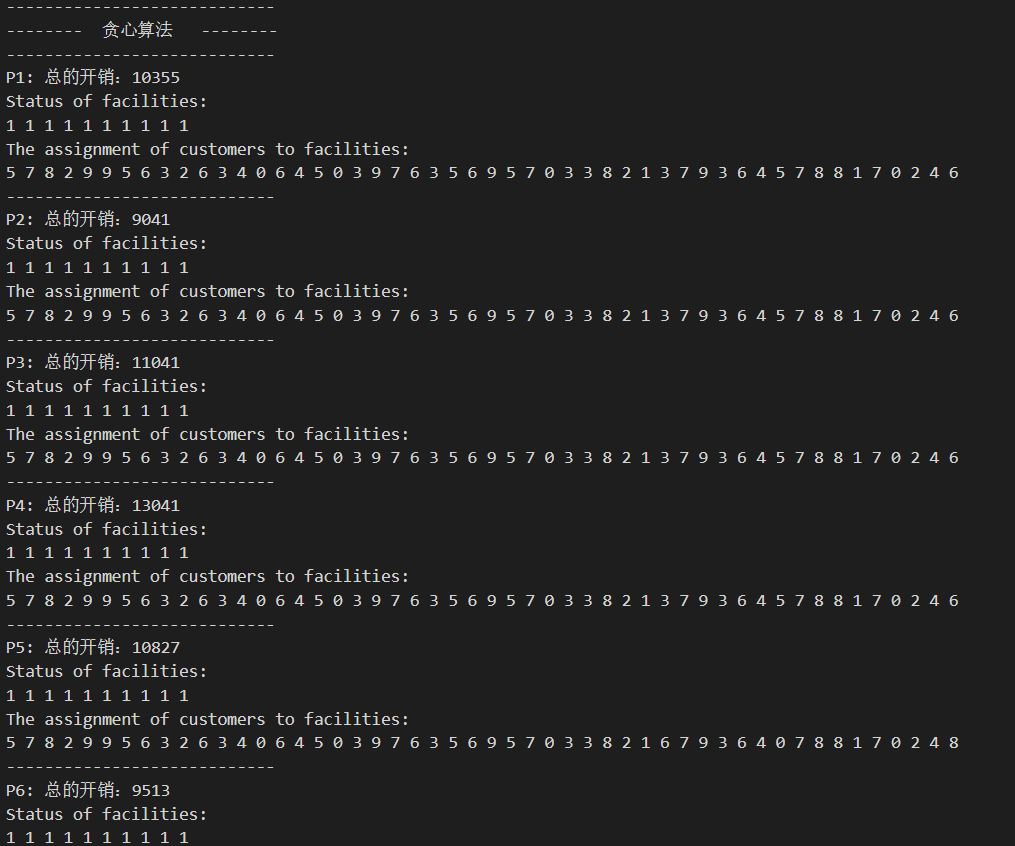
- 剩余的未展示的detail Solution已附在github仓库中。
2. 模拟退火算法
-
Result Table:

-
Detail solution:

- 剩余的未展示的detail Solution已附在github仓库中。
3. 遗传算法
-
Result Table:

-
Detail solution:
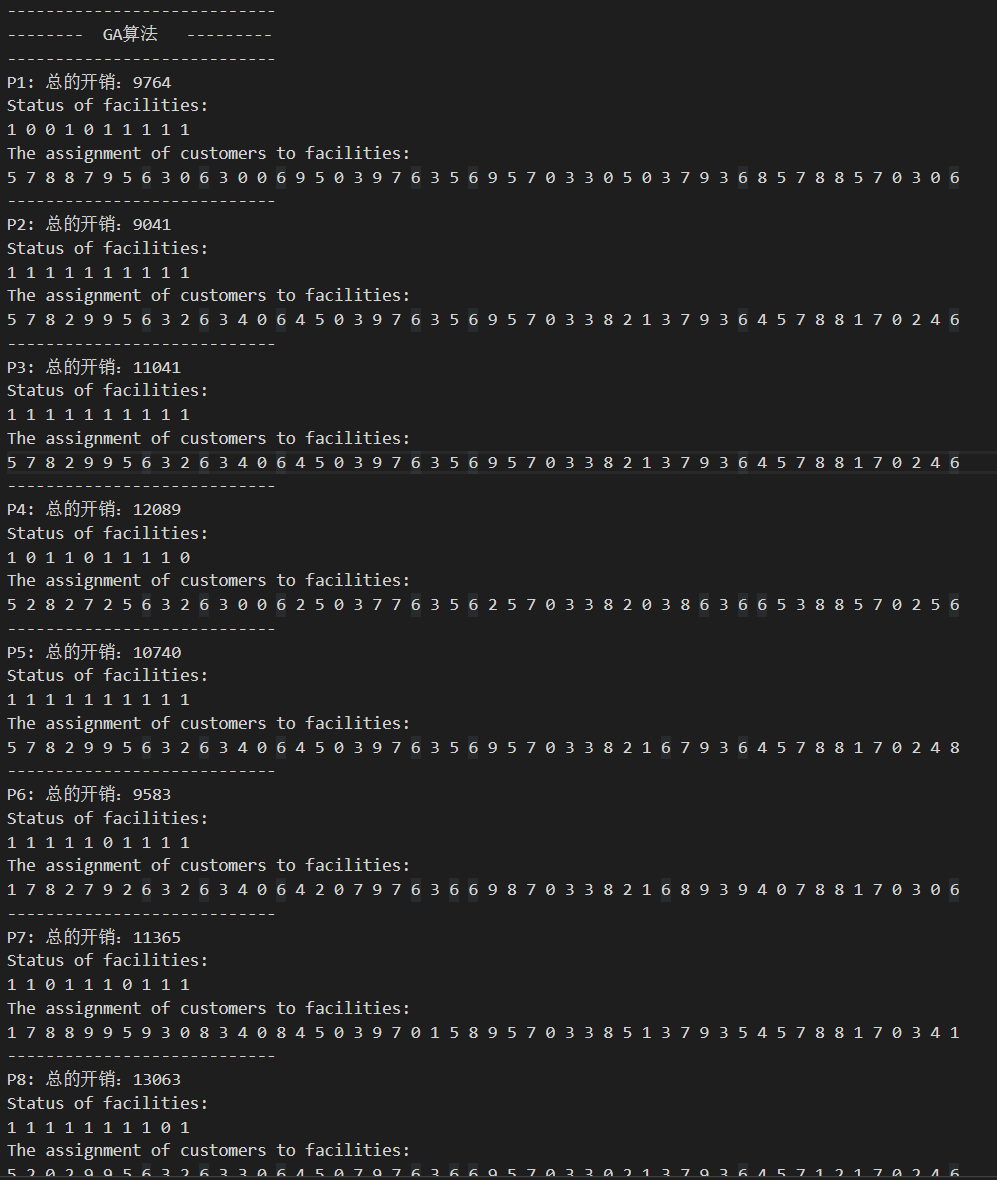
- 剩余的未展示的detail Solution已附在github仓库中。
实验感想
- 分析实验结果可见,GA对贪心算法的优化是很明显的,基因编码短的情况下,找到的最优解甚至比退火要好一些,而在基因编码较长的情况下,甚至会出现比贪心还要高的cost的情况;而模拟退火找到的最优解无论什么情况下都比贪心算法要好,可以看出模拟退火的寻找全局最优解的能力还是很不错的,而且绝大多数情况下,SA的最优解都比GA要好,这次实验结果取的都是各自算法在我测试过程中的最好解,但是毕竟都有随机性,所以总的来说,寻找全局最优解的能力,还是SA > GA > 贪心。
- 本次实验最大的感想便是对遗传算法与模拟退火算法的理解加深了许多。这次实验,我分别使用GA与SA来解决此题,也帮助我更好的理解二者的异同,虽然GA与SA都是牺牲时间来换取精度的随机搜索算法,但是SA有更好的全局搜索最优解的能力,GA虽然有变异的扰动作用,但是GA通过变异实现的扰动作用与SA的领域操作(Metropolis准则——以概率接受新状态)相比,跳出局部最优解的能力还是要差一些,所以在资源充足的情况下,SA搜寻到局部最优解的能力要更好一些
- 在解决此类开放性的问题时,思路真的很重要,有一个好的思路,好的算法,便可以依此为基础把题目结构清晰地分解开,然后再单独实现每一部分的代码,最后合并,整个算法就实现出来。由此也可知,基础是真的非常关键,基础不牢地动山摇,想象力再丰富也无法创造出一个自己的算法出来。
- 查阅资料和与同学交流也非常重要,集思广益,可以交流一下大家的思路,这样也可以开拓一下自己的思维,然后再各自沉浸在各自的解题方法中,最后大家再比对一下各自算法的优劣,乐在其中。
